
복습하기 위해 학부 수업 내용을 필기한 내용입니다.
이해를 제대로 하지 못하고 정리한 경우 틀린 내용이 있을 수 있습니다.
그러한 부분에 대해서는 알려주시면 정말 감사하겠습니다.
▶7.2 지능 에이전트 만들기
7.2.2 다국어 단어 공부 1 - tkinter를 이용한 대화형 인터페이스
tkinter 라이브러리를 활용해 사용자 인터페이스 부착
gtts 라이브러리를 활용해 단어 발음을 들려준다.
# 다국어 단어 공부 : tkinter를 이용한 대화형 인터페이스
import numpy as np
import tensorflow as tf
import tkinter as tk
from tkinter import filedialog
from PIL import Image, ImageTk
import winsound
from gtts import gTTS
import playsound
import os
cnn = tf.keras.models.load_model("my_cnn_for_deploy.h5")
class_names_en = ['airplane','automobile','bird',
'cat','deer','dog','flog',
'horse','ship','truck']
class_names_fr = ['avion','voiture','oiseau',
'chatte','biche','chienne','grenouille',
'jument','navire','un camion']
class_names_de = ['Flugzeug','Automobil','Vogel',
'Katze','Hirsch','Hund','Frosch',
'Pferd','Schiff','LKW']
class_id = 0
tk_img = ''
def process_image():
global class_id, tk_img
fname = filedialog.askopenfilename()
img = Image.open(fname)
tk_img = img.resize([128, 128])
tk_img = ImageTk.PhotoImage(tk_img)
canvas.create_image((canvas.winfo_width()/2, canvas.winfo_height()/2),
image=tk_img, anchor='center')
x_test = []
x = np.asarray(img.resize([32, 32])) / 255.0
x_test.append(x)
x_test = np.asanyarray(x_test)
res = cnn.predict(x_test)
class_id = np.argmax(res)
label_en['text'] = '영어: ' + class_names_en[class_id]
label_fr['text'] = '프랑스어: ' + class_names_fr[class_id]
label_de['text'] = '독일어: ' + class_names_de[class_id]
winsound.Beep(frequency=500, duration=250)
def tts_english():
tts = gTTS(text=class_names_en[class_id], lang='en')
if os.path.isfile('word.mp3'):
os.remove('word.mp3')
tts.save('word.mp3')
playsound.playsound('word.mp3', True)
def tts_french():
tts = gTTS(text=class_names_fr[class_id], lang='en')
if os.path.isfile('word.mp3'):
os.remove('word.mp3')
tts.save('word.mp3')
playsound.playsound('word.mp3', True)
def tts_deutsch():
tts = gTTS(text=class_names_de[class_id], lang='en')
if os.path.isfile('word.mp3'):
os.remove('word.mp3')
tts.save('word.mp3')
playsound.playsound('word.mp3', True)
def quit_program():
win.destroy()
win=tk.Tk()
win.title('다국어 단어 공부')
win.geometry('512x500')
process_button = tk.Button(win, text='영상 선택', command=process_image)
quit_button = tk.Button(win, text='끝내기', command=quit_program)
canvas = tk.Canvas(win, width=256, height=256, bg='cyan', bd=4)
label_en = tk.Label(win, width=16, height=1, bg='yellow', bd=4, text='영어', anchor='w')
label_fr = tk.Label(win, width=16, height=1, bg='yellow', bd=4, text='프랑스어', anchor='w')
label_de = tk.Label(win, width=16, height=1, bg='yellow', bd=4, text='독일어', anchor='w')
tts_en = tk.Button(win, text='듣기', command=tts_english)
tts_fr = tk.Button(win, text='듣기', command=tts_french)
tts_de = tk.Button(win, text='듣기', command=tts_deutsch)
process_button.grid(row=0, column=0)
quit_button.grid(row=1, column=0)
canvas.grid(row=0, column=1)
label_en.grid(row=1, column=1, sticky='e')
label_fr.grid(row=2, column=1, sticky='e')
label_de.grid(row=3, column=1, sticky='e')
tts_en.grid(row=1, column=2, sticky='w')
tts_fr.grid(row=2, column=2, sticky='w')
tts_de.grid(row=3, column=2, sticky='w')
win.mainloop()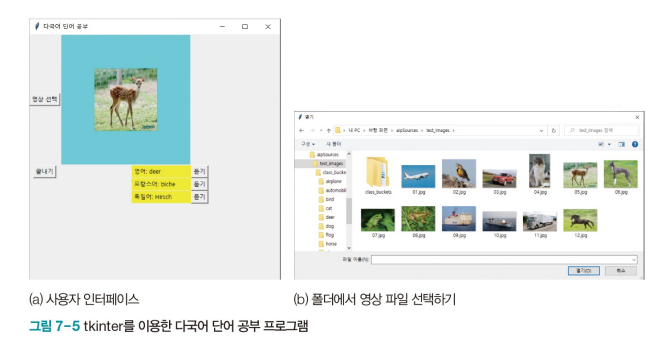
7.2.3 다국어 단어 공부 2 - opencv와 웹캠을 이용한 대화형 인터페이스
웹캠에서 들어오는 영상을 인식하는 방식으로 인터페이스 개선 (웹캠은 opencv로 제어)
# 다국어 단어 공부 : tkinter를 이용한 대화형 인터페이스
import numpy as np
import tensorflow as tf
import tkinter as tk
from tkinter import filedialog
from PIL import Image, ImageTk
import winsound
from gtts import gTTS
import playsound
import os
import cv2
cnn = tf.keras.models.load_model("my_cnn_for_deploy.h5")
class_names_en = ['airplane','automobile','bird',
'cat','deer','dog','flog',
'horse','ship','truck']
class_names_fr = ['avion','voiture','oiseau',
'chatte','biche','chienne','grenouille',
'jument','navire','un camion']
class_names_de = ['Flugzeug','Automobil','Vogel',
'Katze','Hirsch','Hund','Frosch',
'Pferd','Schiff','LKW']
class_id = 0
tk_img = ''
def process_video():
global class_id, tk_img
video = cv2.VideoCapture(0)
while video.isOpened():
success, frame = video.read()
if success:
cv2.imshow('Camera', frame)
key = cv2.waitKey(1) & 0xFF
if key == 27:
break
video.release()
cv2.destroyAllWindows()
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = Image.fromarray(frame)
tk_img = img.resize([128, 128])
tk_img = ImageTk.PhotoImage(tk_img)
canvas.create_image((canvas.winfo_width()/2, canvas.winfo_height()/2),
image=tk_img, anchor='center')
x_test = []
x = np.asarray(img.resize([32, 32])) / 255.0
x_test.append(x)
x_test = np.asanyarray(x_test)
res = cnn.predict(x_test)
class_id = np.argmax(res)
label_en['text'] = '영어: ' + class_names_en[class_id]
label_fr['text'] = '프랑스어: ' + class_names_fr[class_id]
label_de['text'] = '독일어: ' + class_names_de[class_id]
winsound.Beep(frequency=500, duration=250)
def tts_english():
tts = gTTS(text=class_names_en[class_id], lang='en')
if os.path.isfile('word.mp3'):
os.remove('word.mp3')
tts.save('word.mp3')
playsound.playsound('word.mp3', True)
def tts_french():
tts = gTTS(text=class_names_fr[class_id], lang='en')
if os.path.isfile('word.mp3'):
os.remove('word.mp3')
tts.save('word.mp3')
playsound.playsound('word.mp3', True)
def tts_deutsch():
tts = gTTS(text=class_names_de[class_id], lang='en')
if os.path.isfile('word.mp3'):
os.remove('word.mp3')
tts.save('word.mp3')
playsound.playsound('word.mp3', True)
def quit_program():
win.destroy()
win=tk.Tk()
win.title('다국어 단어 공부')
win.geometry('512x500')
process_button = tk.Button(win, text='비디오 선택', command=process_video)
quit_button = tk.Button(win, text='끝내기', command=quit_program)
canvas = tk.Canvas(win, width=256, height=256, bg='cyan', bd=4)
label_en = tk.Label(win, width=16, height=1, bg='yellow', bd=4, text='영어', anchor='w')
label_fr = tk.Label(win, width=16, height=1, bg='yellow', bd=4, text='프랑스어', anchor='w')
label_de = tk.Label(win, width=16, height=1, bg='yellow', bd=4, text='독일어', anchor='w')
tts_en = tk.Button(win, text='듣기', command=tts_english)
tts_fr = tk.Button(win, text='듣기', command=tts_french)
tts_de = tk.Button(win, text='듣기', command=tts_deutsch)
process_button.grid(row=0, column=0)
quit_button.grid(row=1, column=0)
canvas.grid(row=0, column=1)
label_en.grid(row=1, column=1, sticky='e')
label_fr.grid(row=2, column=1, sticky='e')
label_de.grid(row=3, column=1, sticky='e')
tts_en.grid(row=1, column=2, sticky='w')
tts_fr.grid(row=2, column=2, sticky='w')
tts_de.grid(row=3, column=2, sticky='w')
win.mainloop()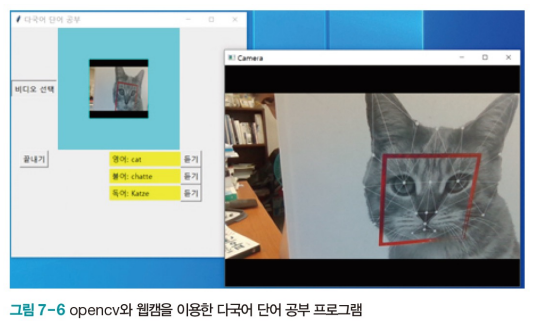
7.2.4 집 지킴이 - YOLOv3을 이용한 침입자 검출
빈집에 사람이 나타나면 경고음을 울려주는 프로그램
# 웹캠을 이용해 침입자 검출하기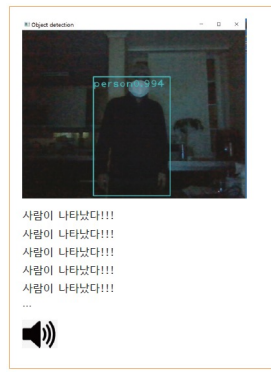
▶7.3 고급 인터페이스를 갖춘 지능 에이전트
인터페이스 방식
- 앞에서는 패키지 소프트웨어 방식의 인터페이스 사용
7.3.1 웹과 앱
웹 프로그래밍
- HTML과 자바스크립트라는 웹 언어에 대한 지식 필요하다.
- HTML은 웹 브라우저에 표시되는 문서를 표현하는 언어이다.
- 자바스크립트는 쌍방향 상호작용을 해주는 언어이다.
- 웹 서비스하려면 서버 필요하다.
- 자신의 컴퓨터를 웹 서버로 설정 또는 glitch.com과 같은 무료 서비스 활용
- 텐서플로 프로그램을 웹과 연결하려면 tensorflow.js를 사용하면 된다.
7.3.2 로봇
로봇은 가장 활동적인 지능 에이전트이다.

지능 로봇의 수준(아래로 가면서 불확실성이 큰 과업 처리)
- 조립용 로봇 : 이동 궤적을 정해주면 충실하게 단순 반복 작업 수행한다.
- 자세가 제멋대로인 부품을 집는 로봇 : 컴퓨터 비전을 통한 인식 필요하다.
- 청소용 로봇
- 카메라, 거리 센서, 적외선 센서 등이 필요하고 검출과 인식 알고리즘 필요하다
- 경로 계획 알고리즘 필요
- 모르는 건물에 진입해 작전 수행하는 빅독
- 위치 파악과 지도 제작을 동시에 수행하는 SLAMsimultaneous localization and mapping 필요하다.
- 휴머노이드
- 혼잡한 공간 이동, 물체 인식과 음성 인식
- 상대의 표정을 인식
로봇 프로그래밍 교육
- 주로 단일 보드 컴퓨터(라즈베리파이, 젯슨, 오드로이드 등)를 탑재한 바퀴 달린 로봇 활용
- 표준 미들웨어인 ROSrobot operating system 상에서 프로그래밍
▶7.4 지식 표현과 추론
지능 에이전트는 지식 베이스가 필요하다. (표현력, 이해의 문제)
지식 표현과 추론
- 인간 지능의 핵심이지만 인공지능에서는 미숙한 분야이다.
- 인간 지능과 인공지능의 격차가 가 장 큰 연구 주제이다.
7.4.1 지식 표현 방법론
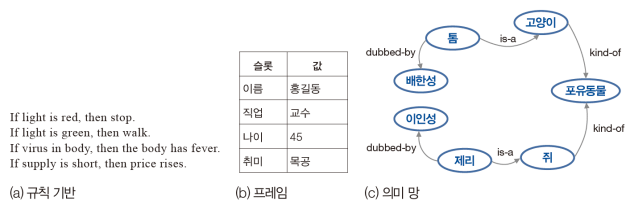
규칙 기반
- if-then 구절로 지식을 표현한다.
- 1980대에 전문가 시스템을 만드는 중요 기술이다. (Dendral, Mycin 등의 전문가 시스템)
프레임
- 슬롯-값 쌍으로 지식 표현한다. (프로그래밍 언어의 구조체 또는 데이터베이스의 관계와 유사하다.)
- KL-One 패키지 : 개념으로 지식을 표현하고 연역적 분류기로 추론 수행한다.
의미망
- 그래프로 지식을 표현한다. (is-a와 kind-of 관계를 주로 사용한다.)
온톨로지
- RDFresource description framework는 방대한 수의 트리플을 표현, 저장, 관리하는 기술
- 주어, 술어, 목적어로 구성된 트리플 사용
온톨로지의 계층 구조
- SPARQL은 RDF에서 동작하는 표준 질의 언어
- OWL은 RDF에서 동작하는 대표적 온톨로지 언 어
- OWL을 구현한 소프트웨어로 Protégé와 지식 그래프
- 온톨로지로 구현한 지식 베이스
- Cyc(최대 규모 지식 베이스 구축 프로젝트였으나 사 실상 실패)
- WordNet(인간 어휘 전반을 상위어, 하위어, 유사어로 연결한 지식 베이스)
7.4.2 지식 그래프
현재 가장 널리 쓰이는 지식 표현 방법
- ex) 구글의 지식 그래프는 2016년 기준으로 700억 개의 사실을 포함한 방대한 지식 베이스
지식 그래프와 추론
- 지식 그래프 구현 방법
- 큐레이션(Cyc, WordNet)
- 협업(Wikidata, Freebase)
- 자연어 처리 (Yago, DBpedia, Knowledge vault)
▶7.5 틈새 없는 협동과 능동성을 갖춘 지능 에이전
틈새 없는 협동 (seamless coordination)
- 컴퓨터 비전과 로봇 손이 협동하는 시각 서보잉 (visual servoing) (예, 수건 개는 로봇)
- 기술 한계
- 인간은 완벽하게 틈새 없는 협동을 한다.
능동성 (proactive)
- 사람은 과업에서 과업으로 틈새 없이 전환한다. (자신이 다음에 벌일 일을 주도적으로 구상한다.)
- 로봇은 매우 제한적으로 능동성 발휘한다.(어떻게 빨래 개는 과업에서 밥 먹는 과업으로 자연스럽게 전환할 수 있을까?)
'컴퓨터공학 > 인공지능' 카테고리의 다른 글
| [인공지능] 8장. 시계열 데이터와 순환 신경망2 - 비트코인 가격 예측 (3) | 2023.05.10 |
|---|---|
| [인공지능] 8장. 시계열 데이터와 순환 신경망1 (1) | 2023.05.09 |
| [인공지능] 7장. 지능 에이전트1 (1) | 2023.05.07 |
| [인공지능] 6장. 컨볼루션 신경망과 컴퓨터 비전4 (1) | 2023.05.07 |
| [인공지능] 1, 2장. 인공지능 (1, 2장 볼만한 내용) (0) | 2023.04.16 |