728x90

복습하기 위해 학부 수업 내용을 필기한 내용입니다.
이해를 제대로 하지 못하고 정리한 경우 틀린 내용이 있을 수 있습니다.
그러한 부분에 대해서는 알려주시면 정말 감사하겠습니다.
▶6.8 물체 검출
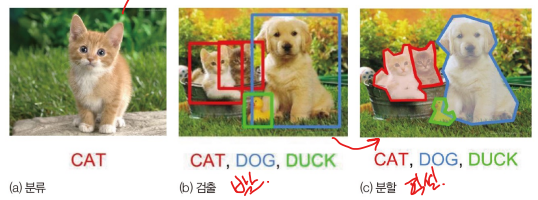
분류(classification), 검출(detection), 분할(segmentaion) 문제
물체 검출을 위한 딥러닝 모델
- R-CNN
- Fast R-CNN
- Faster R-CNN
- YOLO (you Only look Once)
6.8.1 욜로를 이용한 물체 검출
입력 영상을 S*S 격자(grid)로 나눈 S^2개의 격자 방 각각에 대해 B개의 바운딩 박스를 생성한다.
바운딩 박스는 (x, y, w, h, o)의 5개의 값으로 표현한다. (o는 물체일 가능성)
C=80개의 물체 부류
실제 구현에서는 S=7, B=2
→ 49개 격자방 각각은 부류 정보를 표현하는 80-차원 벡터와 바운딩 박스 두 개를 표현하는 10-차원 벡터를 가진다.

YOLOv3
14*14, 258*28, 56*56의 3개 스케일을 사용한다.
각각 yolo_82, yolo_94라는 중간층과 yolo_106이라는 마지막 층에서 추출 가능하다.

728x90
6.8.2 욜로 프로그래밍
import numpy as np
import cv2
classes = []
# 80개의 부류 이름을 읽어온다.
f=open('coco.names.txt', 'r')
classes=[line.strip() for line in f.readlines()]
colors=np.random.uniform(0,255,size=(len(classes),3))
# 테스트할 영상을 읽고 전처리 수행
img=cv2.imread('yolo_test.jpg')
height,width,channels=img.shape
blob=cv2.dnn.blobFromImage(img,1.0/256,(448,448),(0,0,0),swapRB=True,crop=False)
# YOLOv3 모델을 불러온다.
yolo_model=cv2.dnn.readNet('./yolov3.weights','./yolov3.cfg')
layer_names=yolo_model.getLayerNames()
# yolo_82, 94, 106층으 ㄹ알아낸다.
out_layers=[layer_names[i[0]-1] for i in yolo_model.getUnconnectedOutLayers()]
# 테스트 영상을 신경망에 입력
yolo_model.setInput(blob)
# 출력을 output3 객체에 저장
output3=yolo_model.forward(out_layers)
class_ids,confidences,boxes=[],[],[]
for output in output3:
for vec85 in output:
scores=vec85[5:]
class_id=np.argmax(scores)
confidence=scores[class_id]
if confidence>0.5: # 신뢰도가 50% 이상인 경우만 취함
centerx,centery=int(vec85[0]*width),int(vec85[1]*height) # [0,1] 표현을 영상 크기로 변환
w,h=int(vec85[2]*width),int(vec85[3]*height)
x,y=int(centerx-w/2),int(centery-h/2)
boxes.append([x,y,w,h])
confidences.append(float(confidence))
class_ids.append(class_id)
indexes=cv2.dnn.NMSBoxes(boxes,confidences,0.5,0.4)
for i in range(len(boxes)):
if i in indexes:
x,y,w,h=boxes[i]
text=str(classes[class_ids[i]])+'%.3f'%confidences[i]
cv2.rectangle(img,(x,y),(x+w,y+h),colors[class_ids[i]],2)
cv2.putText(img,text,(x,y+30),cv2.FONT_HERSHEY_PLAIN,2,colors[class_ids[i]],2)
cv2.imshow("Object detection", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
728x90
'컴퓨터공학 > 인공지능' 카테고리의 다른 글
| [인공지능] 7장. 지능 에이전트2 (0) | 2023.05.08 |
|---|---|
| [인공지능] 7장. 지능 에이전트1 (1) | 2023.05.07 |
| [인공지능] 1, 2장. 인공지능 (1, 2장 볼만한 내용) (0) | 2023.04.16 |
| [인공지능] 6장. 컨볼루션 신경망과 컴퓨터 비전3 (0) | 2023.04.15 |
| [인공지능] 6장. 컨볼루션 신경망과 컴퓨터 비전2 (0) | 2023.04.13 |