728x90

복습하기 위해 학부 수업 내용을 필기한 내용입니다.
이해를 제대로 하지 못하고 정리한 경우 틀린 내용이 있을 수 있습니다.
그러한 부분에 대해서는 알려주시면 정말 감사하겠습니다.
Time-Series Data and Recurrent Neural Networks
▶8.3 LSTM으로 시계열 예측하기
시계열 데이터를 보고 미래를 예측하는 프로그래밍
- 단일 채널
- 종가 등 한 가지만 고려
- 다중 채널
- 종가, 시가, 고가, 저가를 모두 고려
아래 비트코인 가격 예측 코드는 단순히 교육용으로 작성된 것입니다.
혹시나 실제로 이를 이용하려는 목적으로 사용한다면, 큰일 날 수 있습니다.
8.3.1 단일 채널 비트코인 가격 예측
7일 치 가격을 보고 내일 가격을 예측하는 LSTM 프로그래밍
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 코인데스크 사이트에서 1년치 비트코인 가격 데이터 읽기
f=open("BTC_USD_2019-02-28_2020-02-27-CoinDesk.csv","r")
coindesk_data=pd.read_csv(f,header=0)
seq=coindesk_data[['Closing Price (USD)']].to_numpy() # 종가만 취함
# 시계열 데이터를 윈도우 단위로 자르는 함수
def seq2dataset(seq,window,horizon):
X=[]; Y=[]
for i in range(len(seq)-(window+horizon)+1):
x=seq[i:(i+window)]
y=(seq[i+window+horizon-1])
X.append(x); Y.append(y)
return np.array(X), np.array(Y)
w=7 # 윈도우 크기
h=1 # 수평선 계수
X,Y=seq2dataset(seq,w,h)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout
# 훈련 집합과 테스트 집합으로 분할
split=int(len(X)*0.7)
x_train=X[0:split]; y_train=Y[0:split]
x_test=X[split:]; y_test=Y[split:]
# LSTM 모델 설계와 학습
model=Sequential()
model.add(LSTM(units=128,activation='relu',input_shape=x_train[0].shape))
# 출력층의 activation 매개변수를 생략하여 기본값인 선형 사용
# (출력이 가격(연속값)이어서 회귀 문제이기 때문)
model.add(Dense(1))
model.compile(loss='mae',optimizer='adam',metrics=['mae'])
hist=model.fit(x_train,y_train,epochs=200,batch_size=1,validation_data=(x_test,y_test),verbose=2)
# LSTM 모델 평가
ev=model.evaluate(x_test,y_test,verbose=0)
print("손실 함수:",ev[0],"MAE:",ev[1])
# LSTM 모델로 예측 수행
pred=model.predict(x_test)
print("평균절댓값백분율오차(MAPE):",sum(abs(y_test-pred)/y_test)/len(x_test))
# 학습 곡선
plt.plot(hist.history['mae'])
plt.plot(hist.history['val_mae'])
plt.title('Model mae')
plt.ylabel('mae')
plt.xlabel('Epoch')
plt.ylim([120,800])
plt.legend(['Train','Validation'], loc='best')
plt.grid()
plt.show()
# 예측 결과 시각화
x_range=range(len(y_test))
plt.plot(x_range,y_test[x_range], color='red')
plt.plot(x_range,pred[x_range], color='blue')
plt.legend(['True prices','Predicted prices'], loc='best')
plt.grid()
plt.show()
# 일부 구간을 확대하여 시각화
x_range=range(50,64)
plt.plot(x_range,y_test[x_range], color='red')
plt.plot(x_range,pred[x_range], color='blue')
plt.legend(['True prices','Predicted prices'], loc='best')
plt.grid()
plt.show()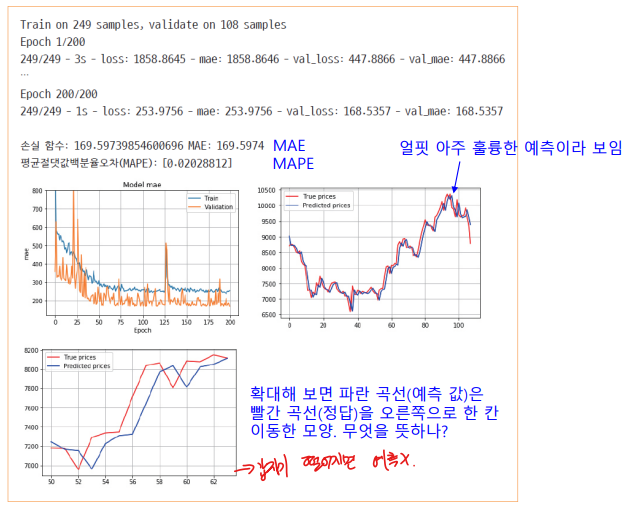
728x90
8.3.2 회귀(regression) 문제에서 성능 평가 (성능 기준)
회귀(regression)
- 독립 변수(입력)와 종속 변수(출력) 사이의 관계를 모델링하는 것이다.
- 종속 변수 값은 일반적으로 연속적인 값(floating number)인 경우가 많다.
성능 기준
- 평균절댓값오차(mean absolute error - MAE) : 스케일 문제에 대처하지 못한다.
- 평균절댓값백분율오차 : 스케일 문제에 대처할 수 있다.

성능 기준
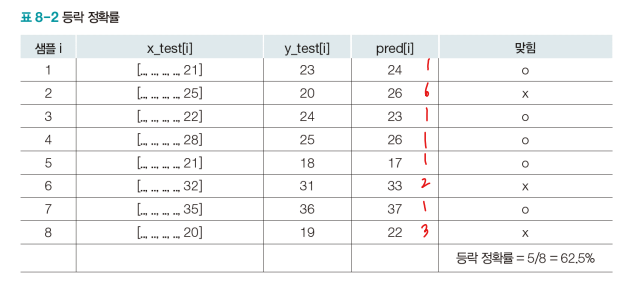
- 등락 정확률
- 등락을 얼마나 정확하게 맞히는지를 측정한다
- 정답값과 예상값의 차이가 e 이하인 경우 맞힘. (| test[i] - pred[i] <= e|)
- 맞힌 경우의 수를 전체 샘플 수로 나눈다.
8.3.3 다중 채널 비트코인 가격 예측
다중 채널을 사용하여 예측
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 코인데스크 사이트에서 1년치 비트코인 가격 데이터 읽기
f=open("BTC_USD_2019-02-28_2020-02-27-CoinDesk.csv","r")
coindesk_data=pd.read_csv(f,header=0)
seq=coindesk_data[['Closing Price (USD)','24h Open (USD)','24h High (USD)','24h Low (USD)']].to_numpy() # 종가, 시가, 고가, 저가를 모두 취함
# 시계열 데이터를 윈도우 단위로 자르는 함수
def seq2dataset(seq,window,horizon):
X=[]; Y=[]
for i in range(len(seq)-(window+horizon)+1):
x=seq[i:(i+window)]
y=(seq[i+window+horizon-1])
X.append(x); Y.append(y)
return np.array(X), np.array(Y)
w=7 # 윈도우 크기
h=1 # 수평선 계수
X,Y = seq2dataset(seq,w,h)
print(X.shape,Y.shape)
print(X[0],Y[0])
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout
# 훈련 집합과 테스트 집합으로 분할
split=int(len(X)*0.7)
x_train=X[0:split]; y_train=Y[0:split]
x_test=X[split:]; y_test=Y[split:]
# LSTM 모델의 설계와 학습
model = Sequential()
model.add(LSTM(units=128,activation='relu',input_shape=x_train[0].shape))
model.add(Dense(4))
model.compile(loss='mae',optimizer='adam',metrics=['mae'])
hist=model.fit(x_train,y_train,epochs=200,batch_size=1,validation_data=(x_test,y_test),verbose=2)
# LSTM 모델 평가
ev=model.evaluate(x_test,y_test,verbose=0)
print("손실 함수:",ev[0],"MAE:",ev[1])
# LSTM 모델로 예측 수행
pred=model.predict(x_test) # LSTM
print("LSTM 평균절댓값백분율오차(MAPE):",sum(abs(y_test-pred)/y_test)/len(x_test))
# 학습 곡선
plt.plot(hist.history['mae'])
plt.plot(hist.history['val_mae'])
plt.title('Model mae')
plt.ylabel('mae')
plt.xlabel('Epoch')
plt.ylim([100,600])
plt.legend(['Train','Validation'], loc='best')
plt.grid()
plt.show()
728x90
'컴퓨터공학 > 인공지능' 카테고리의 다른 글
| [인공지능] 8장. 시계열 데이터와 순환 신경망4 (1) | 2023.05.24 |
|---|---|
| [인공지능] 8장. 시계열 데이터와 순환 신경망3 - LSTM 편곡 (1) | 2023.05.14 |
| [인공지능] 8장. 시계열 데이터와 순환 신경망1 (1) | 2023.05.09 |
| [인공지능] 7장. 지능 에이전트2 (0) | 2023.05.08 |
| [인공지능] 7장. 지능 에이전트1 (1) | 2023.05.07 |