
복습하기 위해 학부 수업 내용을 필기한 내용입니다.
이해를 제대로 하지 못하고 정리한 경우 틀린 내용이 있을 수 있습니다.
그러한 부분에 대해서는 알려주시면 정말 감사하겠습니다.
Time-Series Data and Recurrent Neural Networks
▶8.1 시계열 데이터의 의해
시계열 데이터
- 시간 축을 따라 신호가 변하는 동적 데이터이다.
- 시간 정보가 들어 있는 데이터이다.
- 들어오는 정보의 순서가 중요하다.
- 샘플의 길이가 다를 수 있다. → 달라도 상관이 없다.
시계열 데이터 예제
- 문장 "세상에는 시계열 데이터가 참 많다"
- 시간에 따라 변화가 없지만, 퉁쳐서 시계열 데이터라고 한다.
- Google trend graph(우상단 그래프)
- 심전도, 주식 시세, 음성 데이터
- 유전자 염기 서열(문자열 구조)
- 시간 개념은 없으므로 시계열 데이터는 아니다.
- time은 아니지만 series는 맞기에, 마치 시계열처럼 사용한다.
시계열 데이터를 인식하는 딥러닝 모델
- 순환 신경망(recurrent neural network, RNN)
- LSTM(long short-term memory) : 선별 기억 능력을 갖춰 장기 문맥 처리에 유리하다.
정적 데이터를 인식하는 딥러닝 모델
- 깊은 다층 퍼셉트론, 컨볼루션 신경망
8.1.1 시계열 데이터의 특성
시계열 데이터의 독특한 특성
- 시간 의존성(time dependency) : 시간의 흐름에 따라 데이터 포인트들 간의 종속/관련성
- 추세(Trend) : 시간이 지남에 따라 일정한 방향으로 증가/감소하는 성향
- 계절성(Seasonality) : 일정한 시기 주기마다 반복되는 패턴
- ex) 상추 판매량, 미세먼지 수치, 항공권 판매량 등
- 주기성(Cyclicality) : 불규칙한 주기를 가지는 변동 패턴 (10, 100번에 한 번)
- 문맥 의존성(context dependency) : 데이터 포인트들 값이 주변(문맥)에 의해 영향을 받는다.
- ex) "시계열은 앞에서... 특성이 있다"에서 "시계열"과 "특성이 있다"는 밀접한 관련성이 있다.
- 샘플의 길이가 다르다.
- 요소의 순서가 중요하다.
시계열 데이터 표현
- 가변 길이고 백터의 벡터이다.
- ex) 매일 기온, 습도, 미세먼지 농도를 기록한다면,
- a1 = (23.5, 42, 0.1), a2 = (25.5, 45, 0.08)
8.1.2 미래 예측을 위한 데이터 준비
순환 신경망은 유연한 구조라 여러 문제에 적용 가능하다.
- 대표적 응용은 미래 예측(prediction 또는 forecasting)
- 내일 주가 예측
- 내일 날씨 예측
- 기계의 고장 예측
- 풍속과 풍향 예측 (풍력 발전기의 효율 향상)
- 농산물 가격/수요량 예측 등
- 언어 번역에 응용
- 음성 인식에 응용
- 생성 모델에 응용
- Visual Question Answering
ex) 농산물 수요량 예측 문제에서 데이터
- 농산물 유통업자가 5년 동안 매일 판매량을 기록 → 길이 t = 365 * 5 = 1825인 샘플
- 하나의 긴 샘플을 가지고 어떻게 모델링하고 어떻게 미래를 예측하나?
- 윈도우 크기(w) 단위로 패턴을 잘라 여러 개의 샘플을 수집 (아래 그림 : w = 3)
- 얼마나 먼 미래를 예측할지 지정하는 수평선 계수 h (아래 그림 : h = 1)
- w개를 가지고 h번째 결과를 예측한다.

다중 품목을 표현하는 데이터 (multivariate time series)
- 벡터의 벡터 구조
- ex) 상추와 오이라는 두 품목을 동시에 고려하는 데이터
- 분리해서 풀기 : 상추와 오이의 연관성이 없어 별로 안 좋다.
- 연관성 생각해서 풀기

8.1.3 시계열 데이터 사례 : 비트코인 가격
코인데스크에서 데이터 다운로드
CoinDesk: Bitcoin, Ethereum, Crypto News and Price Data
Leader in cryptocurrency, Bitcoin, Ethereum, XRP, blockchain, DeFi, digital finance and Web 3.0 news with analysis, video and live price updates.
www.coindesk.com
비트코인 가격 데이터 읽기
- pandas 라이브러리 이용
# 8-1(a) 비트코인 가격 데이터 읽기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 코인데스크 사이트에서 다운로드한 1년치 비트코인 가격 데이터 읽기
f = open('BTC_USD_2019-02-28_2020-02-27-CoinDest.csv', 'r')
coindest_data = pd.read_csv(f, header=0)
seq = coindest_data[['Closing Price (USD)']].to_numpy()
print('데이터 길이 : ', len(seq), '\n앞쪽 5개 값 : ', seq[0:5])
# 그래프로 데이터 확인
plt.plot(seq, color='red')
plt.title('Bitcoin Prices (1 year from 2019-02-28)')
plt.xlabel('Days')
plt.ylabel('Price in USD')
plt.show()
윈도우 단위로 잘라 샘플링하는 코드
# 8-1(b) 1년치 비트코인 가격 데이터를 윈도우로 자르기
# 시계열 데이터를 윈도우 단위로 자르는 함수
def seq2dataset(seq, window, horizon):
X = []
Y = []
for i in range(len(seq) - (window + horizon) + 1):
x = seq[i : (i + window)]
y = (seq[i + window + horizon - 1])
X.append(x)
Y.append(y)
return np.array(X), np.array(Y)
w = 2
h = 1
X, Y = seq2dataset(seq, w, h)
print(X.shape, Y.shape)
print(X[0], Y[0])
print(X[-1], Y[-1])▶8.2 순환 신경망
8.2.1 순환 신경망 구조와 동작
순환 신경망 데이터 입력
- 펼쳐서 그리면 이해가 쉽다.
- i 순간에 ai가 입력된다.
- i 순간에 oi가 출력된다.
- a : input (x와 종종 혼용되어 사용한다.)
- h : hidden (latent) variable
- o : output (y와 종종 혼용되어 사용한다.)

★가중치 공유
- 순간마다 서로 다른 가중치를 가지는 것은 아니다.
- 모든 순간이 {U, V, W}를 공유한다.
- 파라미터 개수를 줄이기 위해서
순환 신경망의 동작
- i 순간의 ai는 가중치 U를 통해 은닉층의 상태 hi에 영향을 미친다.
- hi는 가중치 V를 통해 출력값 oi에 영향을 미친.
- hi-1는 가중치 W를 통해 hi에 영향을 미친다.
- 은닉층에서 일어나는 계산

- 출력층에서 일어나는 계산

-은닉층 계산에서 Wh^(i-1) 항을 제외하면 다층 퍼셉트론과 동일하다.
- 이전 순간의 은닉층 상태 h^(i-1)를 현재 순간의 은닉층 상태 hi로 전달하여 시간성을 처리한다.
순환 신경망의 학습
- 학습 알고리즘은 최적의 {U, V, W}를 알아낸다.
- BPTT(back-propagation through time) 알고리즘
- 펼친 순환 신경망은 전방 계산(forward pass) 때, 하나의 큰 다층퍼셉트론으로 취급된다.
- 이때 전체 시계열 데이터를 하나의 input으로 받아들인다.
- 역전파(backpropagation)를 통해 gradient를 계산한다.
- 공유된 가중치(U, V, W)를 update 한다.
파라미터가 적어서 좋지만 학습하기엔 힘들다.
그리고 초기 입력값이 최종에 미치는 영향이 적어져, 처음에 중요한 값이 들어오면 묻힐 가능성이 크다.
→ 가장 큰 단점

8.2.2 선별 기억력을 갖춘 LSTM
순환 신경망의 기억력 한계
- 은닉층 상태에 다음 순간으로 넘기는 기능을 통해 과거를 기억한다.
- 하지만 장기 문맥 의존성(멀리 떨어진 요소가 밀접한 상호작용하는 현상)을 제대로 처리하지 못하는 한계가 있다.
- 계속 들어오는 입력의 영향으로 기억력이 감퇴된다.
LSTM은 게이트라는 개념으로 선별 기억을 확보한다.
- o는 열림, x는 닫힘
- 실제로 게이트는 0~1 사이의 실수값으로 열린 정도를 조절한다.
- 게이트의 여닫는 정도는 가중치로 표현되며 가중치는 학습으로 알아낸다.
LSTM의 가중치
- 순환 신경망의 {U, V, W}에 4개를 추가하여 {U, Ui, Uo, W, Wi, Wo, V}
- i는 입력 게이트, o는 출력 게이트이다.

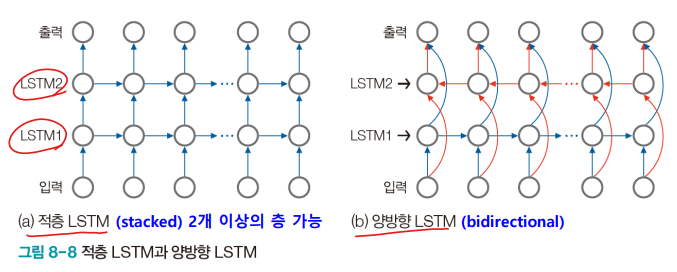
8.2.3 LSTM의 유연한 구조
다양한 구조 설계 가능
- 양방향으로 문맥을 살필 필요가 있는 경우는 양방향 LSTM 사용
- ex) "잘 달리는 이 차는 …"과 "고산지대에서 생산한 이 차는 향기가 좋다."
- 앞 문장은 왼쪽, 뒤 문장은 오른쪽 단어를 보고 각각 car와 tea로 번역한다.
응용문제에 따른 다양한 구조

'컴퓨터공학 > 인공지능' 카테고리의 다른 글
| [인공지능] 8장. 시계열 데이터와 순환 신경망3 - LSTM 편곡 (1) | 2023.05.14 |
|---|---|
| [인공지능] 8장. 시계열 데이터와 순환 신경망2 - 비트코인 가격 예측 (3) | 2023.05.10 |
| [인공지능] 7장. 지능 에이전트2 (0) | 2023.05.08 |
| [인공지능] 7장. 지능 에이전트1 (1) | 2023.05.07 |
| [인공지능] 6장. 컨볼루션 신경망과 컴퓨터 비전4 (1) | 2023.05.07 |