
복습하기 위해 학부 수업 내용을 필기한 내용입니다.
이해를 제대로 하지 못하고 정리한 경우 틀린 내용이 있을 수 있습니다.
그러한 부분에 대해서는 알려주시면 정말 감사하겠습니다.
▶10.2 오토인코더 (Autoencoder)
오토인코더는 입력 패턴과 출력 패턴이 같은 신경망 (모양, 값 모두 같게)
- 사람이 레이블을 달 필요가 없는 비지도 학습
- 고전적인 응용 : 영상 압축, 잡음 제거 등
- 딥러닝 응용 : 특징 추출 또는 생성 모델 (중간에 살짝 변형해 조금 다른 애를 출력한다.)
기본 아이디어
- 입력 데이터를 압축된 표현(representation) 또는 특징으로 인코딩(encoding)
- 압축된 표현은 다시 원래 입력 형태로 디코딩(decoding)
오토인코더 학습
- 입력과 출력의 차이를 최소화하는 방향
10.2.1 오토인코더의 구조와 원리
오토인코더
- 입력 패턴 x를 입력받아 x와 똑같은 또는 유사한 x'를 출력하는 신경망
- 실제로는 은닉층의 노드 개수를 축소하여 설계한다.
- 인코더는 차원을 줄이고 디코더는 차원을 회복한다.
- z 공간을 잠복 공간(latent space)이라 부른다.
- 개수는 줄어들었지만, 원래 값의 중요한 정보를 담는다.
- 차원을 줄이는 이유는 잠복 공간에 표현된 특징들이 데이터 변화에 따른 의미 있는 정보를 담기 위해서이다.
10.2.2 오토인코더 프로그래밍
MNIST를 가지고 오토인코더를 구현한다.
import numpy as np
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input,Dense,Flatten,Reshape,Conv2D,Conv2DTranspose
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
# MNIST 데이터를 읽고 신경망에 입력할 준비
(x_train,y_train),(x_test,y_test)=mnist.load_data()
x_train=x_train.astype('float32')/255.
x_test=x_test.astype('float32')/255.
x_train=np.reshape(x_train,(len(x_train),28,28,1))
x_test=np.reshape(x_test,(len(x_test),28,28,1))
zdim=32 # 잠복 공간의 차원
# 오토인코더의 인코더 부분 설계
encoder_input=Input(shape=(28,28,1))
x=Conv2D(32,(3,3),activation='relu',padding='same',strides=(1,1))(encoder_input)
x=Conv2D(64,(3,3),activation='relu',padding='same',strides=(2,2))(x)
x=Conv2D(64,(3,3),activation='relu',padding='same',strides=(2,2))(x)
x=Conv2D(64,(3,3),activation='relu',padding='same',strides=(1,1))(x)
x=Flatten()(x)
encoder_output=Dense(zdim)(x)
model_encoder=Model(encoder_input,encoder_output)
model_encoder.summary()
# 오토인코더의 디코더 부분 설계
decoder_input=Input(shape=(zdim,))
x=Dense(3136)(decoder_input)
x=Reshape((7,7,64))(x)
x=Conv2DTranspose(64,(3,3),activation='relu',padding='same',strides=(1,1))(x)
x=Conv2DTranspose(64,(3,3),activation='relu',padding='same',strides=(2,2))(x)
x=Conv2DTranspose(32,(3,3),activation='relu',padding='same',strides=(2,2))(x)
x=Conv2DTranspose(1,(3,3),activation='relu',padding='same',strides=(1,1))(x)
decoder_output=x
model_decoder=Model(decoder_input,decoder_output)
model_decoder.summary()
# 인코더와 디코더를 결합하여 오토인코더 모델 구축
model_input=encoder_input
model_output=model_decoder(encoder_output)
model=Model(model_input,model_output)
# 오토인코더 학습
model.compile(optimizer='Adam',loss='mse')
model.fit(x_train,x_train,epochs=5,batch_size=128,shuffle=True,validation_data=(x_test,x_test))
# 복원 실험 1: x_test를 복원하는 예측 실험
decoded_img=model.predict(x_test)
import matplotlib.pyplot as plt
n=10
plt.figure(figsize=(20, 4))
for i in range(n):
plt.subplot(2, n, i+1)
plt.imshow(x_test[i].reshape(28, 28),cmap='gray')
plt.xticks([]); plt.yticks([])
plt.subplot(2, n, i + n+1)
plt.imshow(decoded_img[i].reshape(28, 28),cmap='gray')
plt.xticks([]); plt.yticks([])
plt.show()Functional API 방식으로 코딩
- 오토인코더에서는 신경망의 중간층의 결과에 접근할 필요가 있어 Function API 방식으로 코딩해야 한다.
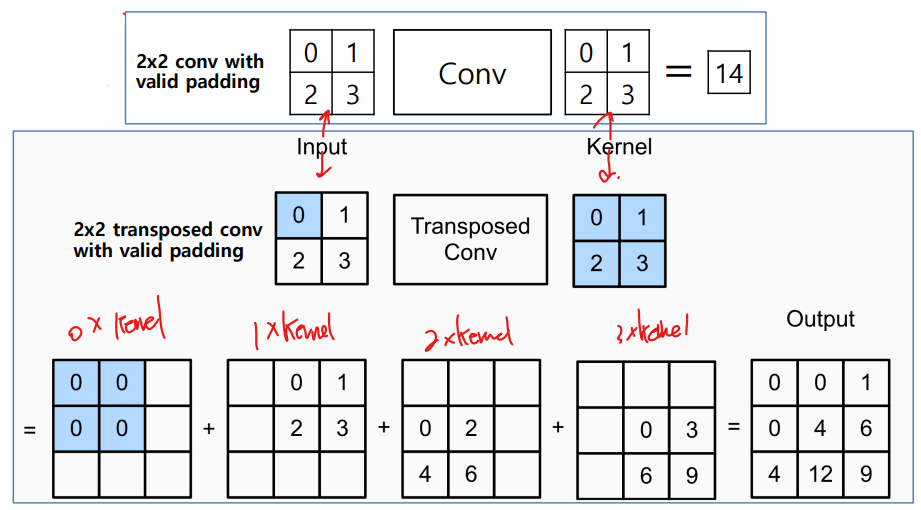
Transposed Convolution
Convolution (Conv2D) vs. Transposed Convolution (Conv2DTranspose)
- Convolution은 커널(필터)을 사용하여 입력 데이터에 대해 수행되는 작업이다.
- 새 출력 매트릭스를 생성하기 위해 입력을 가로질러 슬라이드 된다.
- Transposed convolution은 입력 값을 분배하고 더 큰 영역에 입력을 분산한다.
- 더 큰 출력 매트릭스를 생성하는 컨볼루션의 대략적인 역방향 연산이다.
10.2.3 생성 모델로서 오토인코더
위 코드의 32차원의 잠복 공간의 의미
- 28 * 28(= 784) 차원을 32차원으로 축소
- 원래 패턴을 아주 비슷하게 복원하므로 잠복 공간은 원래 패턴을 충실하게 표현하는 고수준 특징으로 간주할 수 있다.
- 예를 들어, 첫 번째 차원 z1은 획의 둥근 정도, 두 번째 차원 z2는 획의 두께 등
- 따라서 디코더를 떼어내고 인코더 부분만 취하여 특징 추출기로 활용 가능하다.
- 뒤에 다층 퍼셉트론 또는 SVM을 붙이면 훌륭한 필기 숫자 인식기가 된다.
- 현대 딥러닝은 오토인코더를 사용하지 않더라도 높은 성능을 달성할 수 있어 특징 추출기로 활용하는 사례가 줄고 있다.
- Deep CNN 모델에서 최종 결과를 출력하기 전 출력 결과를 사용함 (ex. VGGNet)
- 대신 생성 모델로 많이 사용한다.
오토인코더로 새로운 샘플 생성
- 학습된 디코더로 새로운 샘플을 생성하는 프로그램
# 생성 실험 1: 첫 번째 샘플의 잠복 공간 표현에 잡음을 섞어 새로운 샘플 생성
x0=x_test[0]
z=model_encoder.predict(x0.reshape(1,28,28,1))
print(np.round(z,3))
zz=np.zeros((20,zdim))
for i in range(20):
zz[i]=z[0]+(i-10)/10.0
generated_img=model_decoder.predict(zz)
plt.figure(figsize=(20, 4))
for i in range(20):
plt.subplot(2,10,i+1)
plt.imshow(generated_img[i].reshape(28,28),cmap='gray')
plt.xticks([]); plt.yticks([])
plt.title('noise='+str((i-10)/10.0))
plt.show()
# 생성 실험 2: 같은 부류의 두 샘플 사이를 보간하여 새로운 샘플 생성
x4_6=np.array((x_test[4],x_test[6]))
z=model_encoder.predict(x4_6)
zz=np.zeros((20,zdim))
for i in range(20):
alpha=i/(20.0-1.0)
zz[i]=(1.0-alpha)*z[0]+alpha*z[1]
generated_img=model_decoder.predict(zz)
plt.figure(figsize=(20, 4))
for i in range(20):
plt.subplot(2,10,i+1)
plt.imshow(generated_img[i].reshape(28,28),cmap='gray')
plt.xticks([]); plt.yticks([])
plt.title('alpha='+str(round(i/(20.0-1.0),3)))
plt.show()
위 코드가 생성한 샘플의 품질 평가
- 실험 1
- 7과 비슷한 샘플이 생성된다.
- 잡음이 0.3 근방에서 패턴이 왜곡되기 시작하고 잡음이 더 커지면 형편없는 모양이 된다.
- 실험 2
- 서로 다른 모양의 4 패턴이 서서히 변함을 확인한다.
- Alpha가 0.5 근방에서 획이 끊어져 품질이 떨어지는 현상
결론적으로
- 오토인코더는 생성 모델로서 가능성이 있다.
- 잠복 공간의 점들 중에 품질이 떨어지는 것이 다수 있다.
▶10.3 생성 적대 신경망
2014년에 Ian Goodfellow는 생성 적대 신경망(GAN)을 발표
- GAN(generative adversarial network)은 2개의 신경망이 적대적인 관계에서 학습하는 생성 모델
- 이후 개량된 매우 많은 GAN 모델이 발표됐다.
10.3.1 동기와 원리
GAN의 원리
- Generator network(생성망) G와 discriminator network(판별망/분별망) D
- 두 개 network가 서로 적대적인 관계를 가지도록 한다.
- G, D 두 개의 network가 엇갈려서 학습되며, 서로 경쟁하면서 학습한다.
- G는 D를 속일 수 있을 정도로 품질이 높은 가짜 샘플을 생성한다.
- D는 G가 만든 가짜 샘플을 높은 정확률로 맞힌다.
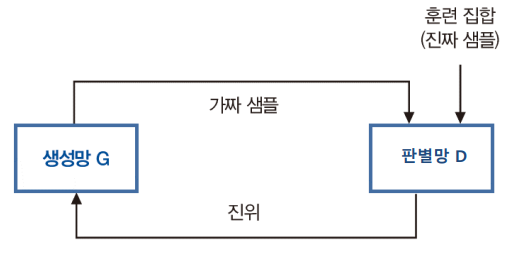
- 위조지폐범과 경찰에 비유
- 현실 세계와 달리 위조지폐범에 해당하는 생성망이 승리해야 한다.
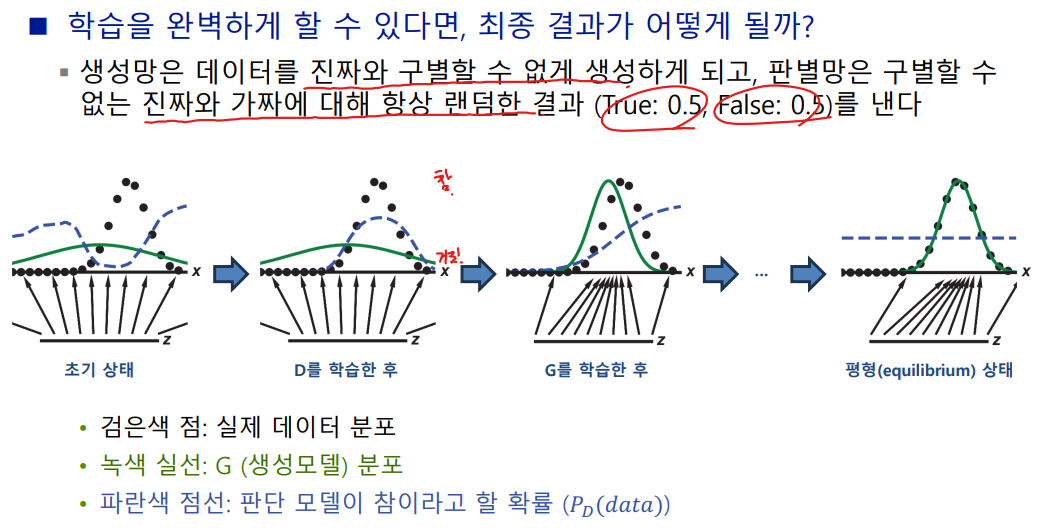
- 학습을 완벽하게 할 수 있다면, 최종 결과가 어떻게 될까?
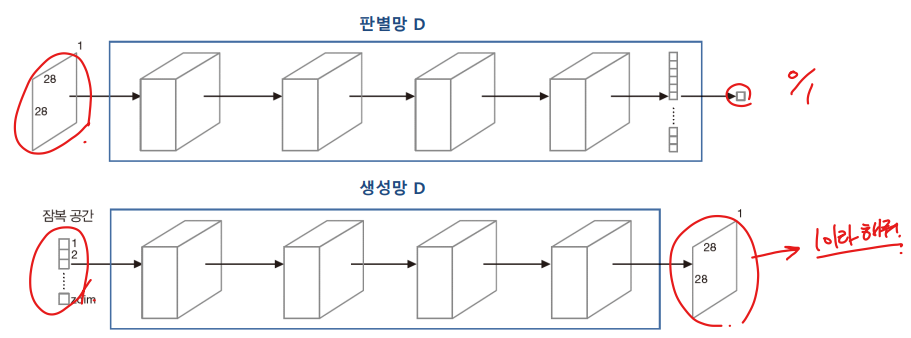
구조(MNIST를 예로 사용하여 설명)
- 판별망 D
- 입력은 28*28 영상. 출력 노드는 1개(1은 진짜, 0은 가짜, 활성 함수로 sigmoid 사용한다.)
- 생성망 G
- 입력은 zdim-차원의 잠복 공간의 한 점의 좌표. 출력은 28*28 영상
- 오토인코더와 비슷하여 구조를 코딩하는 일은 쉽다.
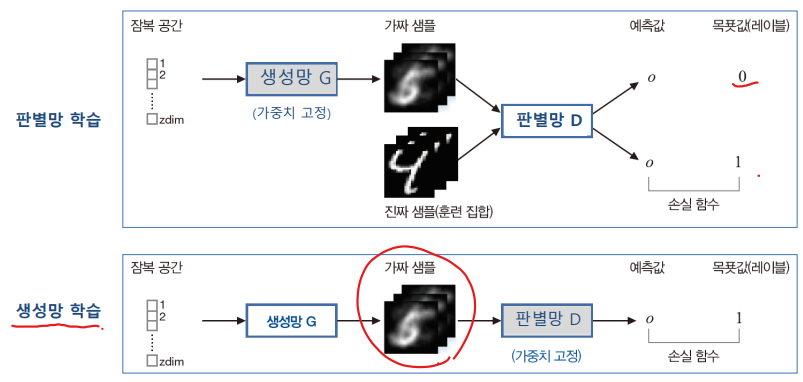
학습
- D와 G를 번갈아가면서 학습한다.
- D 학습할 때는 G의 가중치를 고정. G 학습할 때는 D의 가중치를 고정.
- 판별망 D의 학습 : 이진(진짜와 가짜) 분류한다.
- 진짜 샘플과 가짜 샘플 모두를 가지고 학습한다.
- 생성망 G의 학습은 복잡하다.
- G가 생성한 가짜 샘플에 레이블 1을 붙여 학습한다.
- 즉 분별망을 속이는 학습
GAN 최소극대화 목적함수 (Minimax Objective Function)

- 판별 결과는 확률값과 같이 0에서 1 사이의 실수값
- 상기 목적함수는 판별망이 잘 분류할수록 값이 커지고, 생성망이 판별망을 잘 속일 수 록 값이 작아진다.
- 판별망은 목적함숫값을 최대화하는 것이 목적
- 생성망은 목적함숫값을 최소화하는 것이 목적
- 각 parameter를 gradient ascent와 gradient descent 방법을 적용하여 판별망과 생성망을 번갈아가며 학습한다.
'컴퓨터공학 > 인공지능' 카테고리의 다른 글
| [인공지능] 10장. 생성 모델(Generative Model) 3 (1) | 2023.06.07 |
|---|---|
| [인공지능] 10장. 생성 모델(Generative Model) 1 (0) | 2023.06.04 |
| [인공지능] 9장. 강화 학습(Reinforcement Learning) 3 (0) | 2023.06.04 |
| [인공지능] 9장. 강화 학습(Reinforcement Learning) 2 (0) | 2023.05.30 |
| [인공지능] 9장. 강화 학습(Reinforcement Learning) 1 (0) | 2023.05.30 |