
복습하기 위해 학부 수업 내용을 필기한 내용입니다.
이해를 제대로 하지 못하고 정리한 경우 틀린 내용이 있을 수 있습니다.
그러한 부분에 대해서는 알려주시면 정말 감사하겠습니다.
인공신경망 : ANN (Artificial Neural Network)
사람의 뇌가 동작하는 방식을 그대로 흉내 내어 만든 수학적 모델
뉴런과 시냅스 : neuron and synapse
- 사람의 뇌는 뉴런(신경세포)들이 서로 연결되어 다른 뉴런들과 상호작용
- 입력으로 받은 전기 신호를 적당히 처리하여 다른 뉴런에 전달한다.
- 신호를 전달하려면 입력으로 받은 전기 신호의 합이 일정 수준을 넘어야 한다.


퍼셉트론 : Perceptron
뉴런의 동작 방식을 모방하여 만든 수학적 모델
입력값 : x1, x2, ⋯ , xn
가중치 : w1, w2, ⋯ , wn
- 입력값의 합을 구할 때, 해당 입력값을 강화하거나 약화하기 위해 곱하는 값
- y = f(x1, x2, ⋯ , xn) = w1x1 + w2x2 + ⋯ wnxn
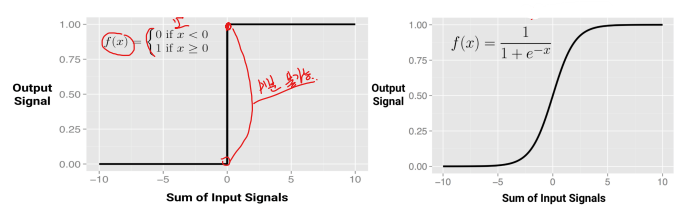
활성 함수 : Activation Function
- 𝑦의 값이 임계값(threshold) 보다 크면 1, 아니면 0을 출력하는 함수
출력값 : 𝑦 = 1이면 다음 퍼셉트론으로 전달하고, 𝑦 = 0이면 전달하지 않는다.
활성 함수 : Activation Function
입력신호의 총합을 바탕으로 출력값을 0 또는 1로 결정해 주는 함수
시그모이드 함수 : 미분가능(differentiable)한 성질을 가진다.
활성 함수 : ReLU 함수
교정된 선형 단위 함수 : Rectified Linear Unit
시그모이드 함수의 경사 손실 현상 : Vanishing Gradient
- 경사하강법으로 최적의 파라미터를 찾을 때 기울기가 0에 가까워진다.
ReLU : 0보다 큰 값은 출력값과 같아지도록 한다. (경사 손실을 줄여준다.)

소프트 플러스 함수 : ReLU 함수를 미분 가능하도록 변형
- y = log(1 / (1 + e^x))


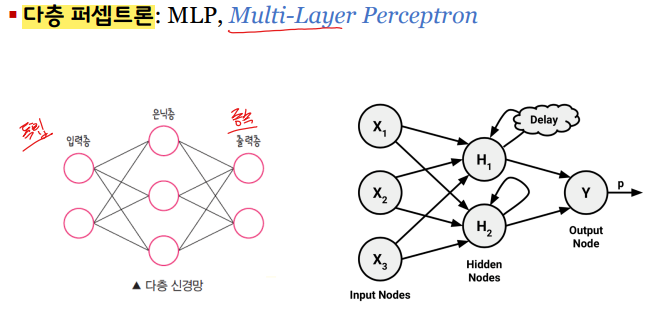
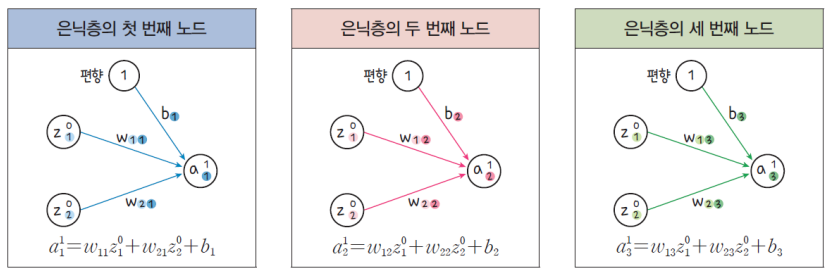
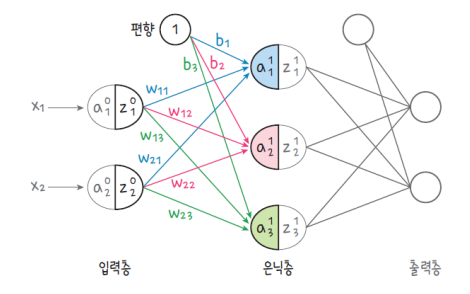
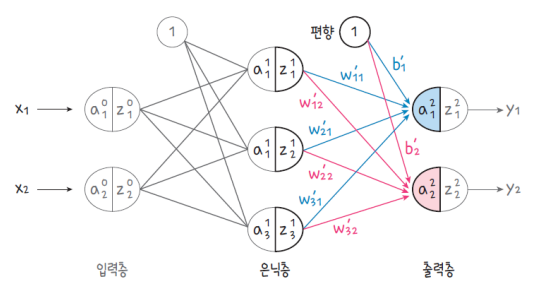
다층 퍼셉트론의 구성
입력층 : Input Layer
- 신호가 입력되는 곳
은닉층 : Hidden Layer
- 입력층의 신호들을 모아서 출력층으로 신호를 전달하는 곳
- 노드가 많을수록 더 결과가 정확하겠지만, 계산량도 많아진다.
출력층 : Output Layer
- 은닉층으로부터 받은 값을 출력해 주는 곳
인공신경망(ANN)의 네트워크 토폴로지 : Network Topology
몇 개의 계층으로 구성할 것인가? 은닉층은 여러 개 있을 수 있다.
네트워크의 각 계층별로 몇 개의 노드를 둘 것인가?
정보는 순방향으로만 흐를 것인가, 역방향으로만 흐를 것인가?
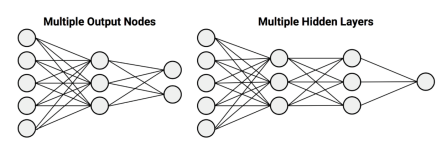
인공신경망의 순전파 : Feed Forward
정보의 흐름이 입력층에서 출력층까지 순방향으로 진행
강화 학습과 딥 러닝
강화 학습 : Reinforcement Learning
- 행동(action)에 따른 보상(reward)을 줌으로써,
- 보상을 극대화하기 위해 동적으로 학습을 하며 행동을 조정한다.
딥 러닝 : Deep (Reinforcement) Learning
- DNN(Deep Neural Network)을 이용한 강화 학습 방법
- DNN = MLP + Backpropagation
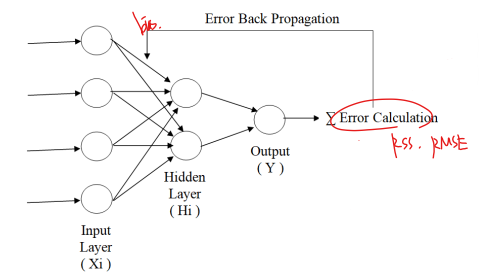
역전파 : Back-propagation
출력값과 실제값의 오차(error)를 역으로 전달해 학습하는 방법
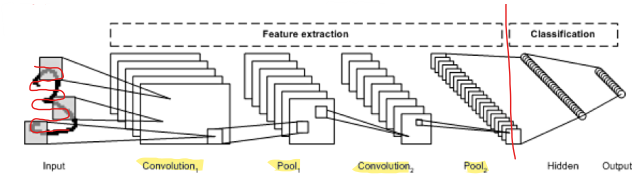
합성곱 신경망 : CNN (Convolutional Neural Network)
주로 이미지 인식에 많이 사용되는 심층 신경망
합성곱층과 풀링층을 반복적으로 조합해서 다층 신경망을 구성
- Convolutional Layer : 입력 이미지에 필터를 적용해 활성 함수를 반영한다.
- Pooling Layer : 합성곱층의 출력크기를 줄이거나 특정 데이터를 강조한다.
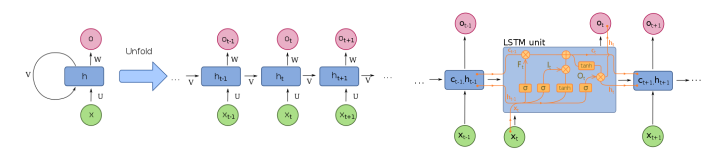
순환 신경망 : RNN (Recurrent Neural Network)
필기체 인식이나 음성 인식과 같은 시계열 응용에 많이 사용되는 심층 신경망
순환적 구조를 가지고 있어서 신경망 내부에 상태를 저장할 수 있게 해 준다.
LSTM : Long Short-Term Memory
- 망각 게이트를 추가해서 장기 기억과 단기 기억을 가질 수 있다.
가중치와 편차의 강화학습
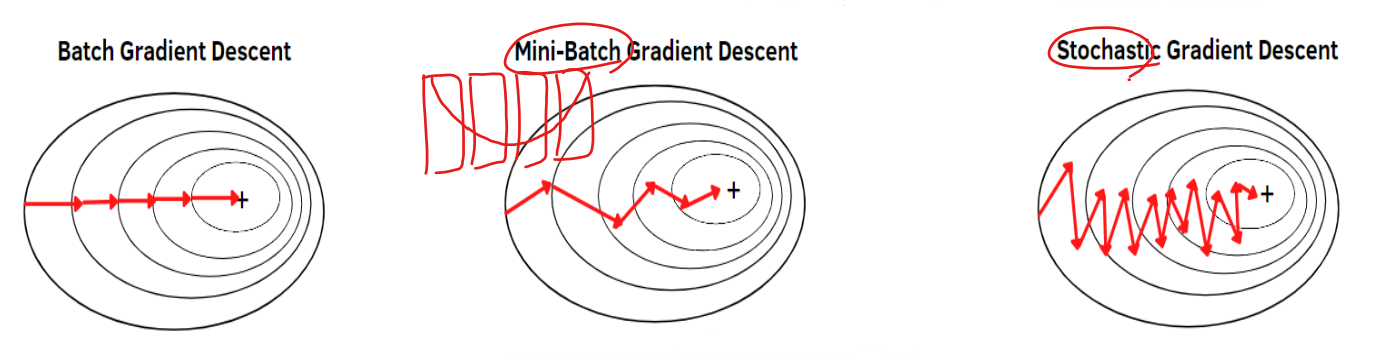
SGD : Stochastic GRadient Descent
- Batch GD : 손실 함수를 계산할 때 전체 훈련 데이터셋(batch)을 사용
- Mini-Batch GD : 전체 데이터 대신 mini-batch로 손실 함수 계산
- Stochastic GD : Mini-Batch에 확률을 도입해서 손실함수 계산
L-BFGS-B : Limited-memory BFGS extended
- 비선형 최적화 알고리즘 : nonlinear optimization
- L-BFGS : quasi-Newton 방법인 BFGS의 Limited Memory 버전
Adam : Adaptive Moment Estimastion
- AdaGrad(Adpative Gradient) : 경사 하강할 때 step size를 다르게 설정
- Momentum : 경사 하강을 하는 과정에 일종의 관성을 주는 방법
- Adam : 위 두 가지를 동시에 적용하는 최적화 방법
학습률 : Learning Rate
경사 하강을 할 때 움직이는 점의 보폭(step size)을 결정하는 상수
학습률의 크기에 비례하여 각 epoch마다 보폭을 조절한다.
- 학습률이 작을수록 학습 시간이 길어지지만, 정확도는 높아진다.
- 학습률이 높을수록 학습 시간은 줄어들지만, 정확도가 떨어진다.
이미지 간의 유사도 측정
이미지 임베딩 : Image Embedding
- 임베딩 : 구조화되어 있지 않은 비정형 데이터로부터 데이터의 특징을 추출
- 이미지 임베딩 : 이미지 데이터의 특성을 반영한 벡터를 생성하는 것
개와 고양이 이미지 임베딩
- 개와 고양이의 이미지에서 각 픽셀 간의 패턴을 특성으로 찾아내기
- 찾아낸 특성을 기반으로 각 이미지 간의 유사도를 측정
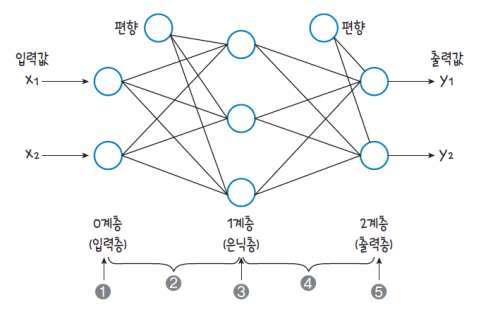
출력층의 구성
원-핫-인코딩 : One-Hot-Encoding
- 데이터를 수많은 0과 한 개의 1의 값으로 구분하는 인코딩 방법
- 범주형 데이터의 범주가 3개라면 3차원 벡터로 표현
- IRIS : setosa=(1, 0, 0), versicolor=(0, 1, 0), virginica=(0, 0, 1)
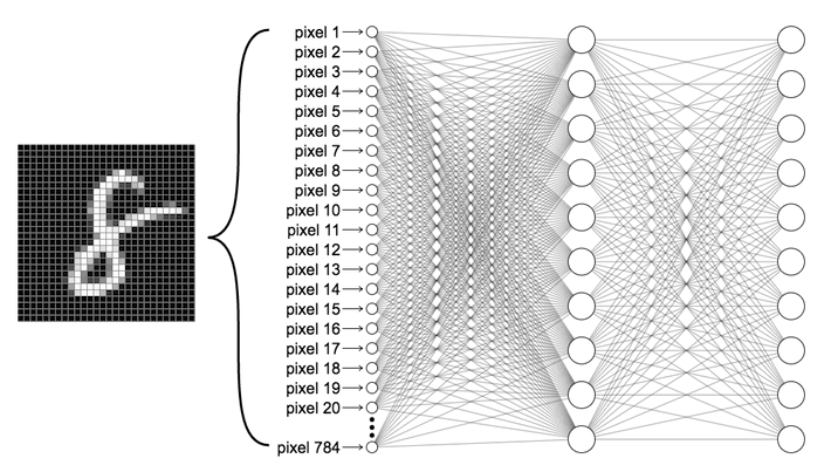
입력층의 구성
픽셀 하나당 하나의 입력: 총 784개의 입력값
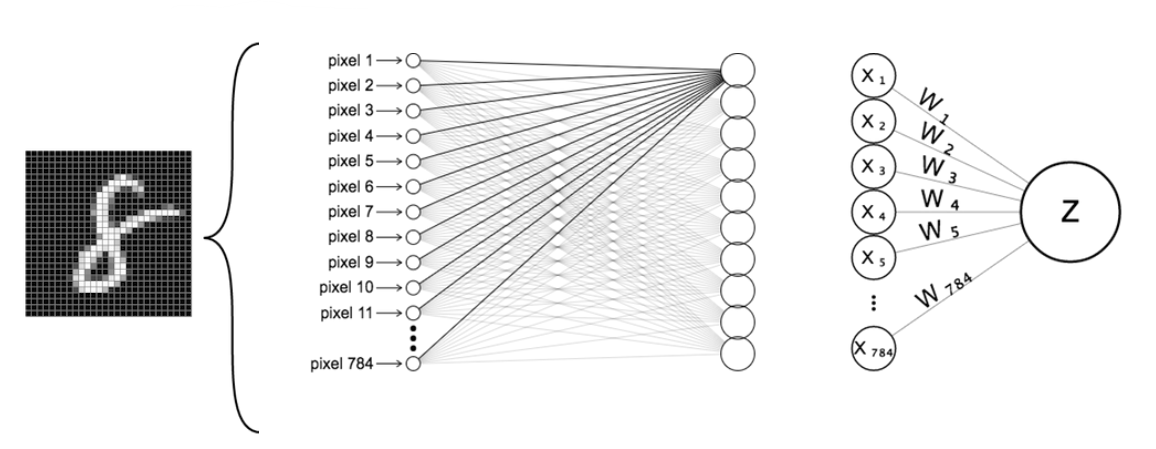
신경망의 구성
DNN을 구성하는 각종 파라미터 설정: 뉴런의 수, 활성 함수, 학습 방법 등
'컴퓨터공학 > 데이터과학기초' 카테고리의 다른 글
| [데이터과학기초] 네트워크 분석 (5) | 2023.01.10 |
|---|---|
| [데이터과학기초] 텍스트 분석 (0) | 2023.01.10 |
| [데이터과학기초] 군집 분석 (Clustering) (2) | 2023.01.09 |
| [데이터과학기초] 로지스틱 회귀와 분류 (0) | 2023.01.02 |
| [데이터과학기초] 선형 회귀와 예측 (0) | 2022.12.30 |