728x90

복습하기 위해 학부 수업 내용을 필기한 내용입니다.
이해를 제대로 하지 못하고 정리한 경우 틀린 내용이 있을 수 있습니다.
그러한 부분에 대해서는 알려주시면 정말 감사하겠습니다.
▶관계형 데이터 모델
- 1970년에 IBM의 E.F.Codd에 의해 처음 제안되었다.
- 외형적으로는 단순한 테이블의 구조로 표현하지만,
- 내부적으로는 릴레이션과 수학적인 이론을 기초로 하고 있다.
- 학생(Student) 테이블
- 테이블 : 릴레이션 (relation)
- 테이블의 열 (또는 필드) : 애트리뷰트 (atrribute)
- 테이블의 행 (도는 레코드) : 튜플 (tuple)
- "20181234", "김철수" : 애트리뷰트의 값 (value)
- 더 이상 분해할 수 없는 원자 값(atomic value)만을 허용한다.

- 도메인 (domain)
- 하나의 애트리뷰트가 취할 수 있는 같은 타입의 모든 원자들의 집합
- ex1. 학번의 도메인 : 8자리 정수의 집합
- ex2. 성명의 도메인 : 5자리 문자열의 집합
- 릴레이션 Student의 정의 예
- 릴레이션 이름 : 학생(student)
- 애트리뷰트 이름 : 학번(sno), 성명(sname), 학과(sdept), 전화번호(tel)
- 도메인 : INTEGER, CHAR(5), CHAR(20),...
- 하나의 도메인에 대하여 둘 이상의 애트리뷰트가 정의될 수 있다.
- ex. sdept, stel은 같은 도메인 CHAR(20)으로 정의되어있다.
- 한 릴레이션에서는 모든 애트리뷰트들의 이름은 반드시 달라야 한다.
- DBMS에 DDL로 정의
create table student(
sno integer,
sname char(10),
sdept char(20),
stel char(20)
);728x90
▶릴레이션의 개념
- 릴레이션 R의 스키마
- 릴레이션 이름 R과 일정수의 애트리뷰트 A1, A2,..., An의 집합으로 구성된다.
- R(A1, A2,..., An)으로 표기한다.
- ex. 학생(학번, 이름,..., 전화번호)
- 각 애트리뷰트 Ai(i = 1,..., n)는 도메인 D1, D2,..., Dn의 한 도메인 Di와 대응된다.
- 하나의 튜플은 각 애트리뷰트에 대응하는 값, <v1, v2,..., vn>으로 구성된다.
- 각 vi는 애트리뷰트 Ai의 값으로서 Ai를 정의하고 있는 도메인 Di의 한 원소 값이다.
▶학생(Student) 릴레이션
- 도메인
- 학번(sno)의 도메인 : integer
- 성명(sname)의 도메인 : char(5)
- 학과(sdept)의 도메인 : char(20)
- 전화번호(stel)의 도메인 : char(20)
- 학생(학번, 성명, 학과, 전화번호)으로 표기한다.
- 릴레이션 이름 : 학생(student)
- 4개의 애트리뷰트 이름 : 학번, 성명, 학과, 전화번호
- 인스턴스 : 6개의 튜플로 구성
- 각 튜플 : 4개의 애트리뷰트 값(학번, 성명, 학과, 전화번호)으로 구성
- 릴레이션 R의 차수(degree) : 애트리뷰트(또는 도메인)의 개수 (4개)
- 릴레이션 R의 카디널리티(cardinality) : 튜플의 수 (6개)
▶릴레이션의 특성
- 튜플의 유일성
- 한 릴레이션에 포함된 튜플들은 모두 상이하다.
- 두 개의 똑같은 튜플은 한 릴레이션에 포함될 수 없다.
- 튜플의 무순서성
- 한 릴레이션에 포함되어 있는 튜플 사이에는 순서가 없다.
- 튜플 순서가 바뀌어도 동일한 릴레이션으로 인식된다.
- 애트리뷰트의 무순서성
- 한 릴레이션을 구성하는 애트리뷰트 사이에는 순서가 없다.
- 애트리뷰트는 순서가 아니라 이름에 의해 참조된다.
- 애트리뷰트의 원자성
- 모든 애트리뷰트 값은 원자 값이다.
- 애트리뷰트의 값으로 반복 그룹, 즉 집합이 될 수 없다.
▶정규화(normalization) 릴레이션
- 정규화 릴레이션
- 반복 그룹(집합)을 애트리뷰트 값으로 허용하지 않는 릴레이션
- 정규화
- 비정규 릴레이션을 정규 릴레이션으로 변환하는 과정
- 널(null) 값
- 애트리뷰트의 값이 없는 경우 사용하는 특별한 값
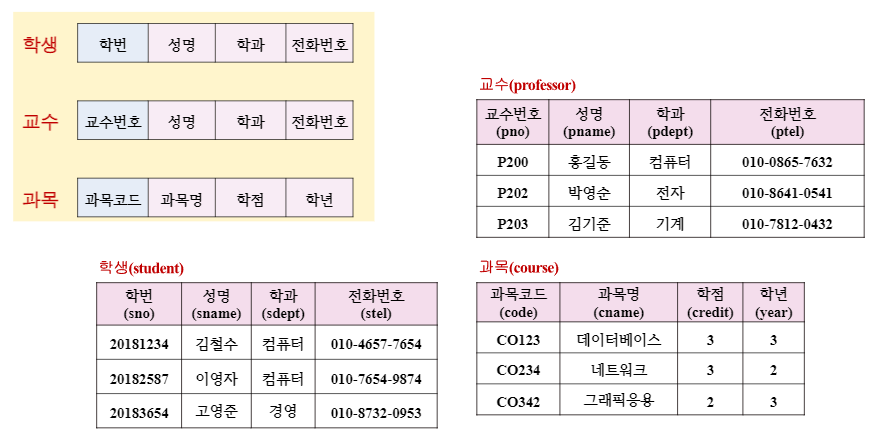
▶개체 릴레이션
- 튜플의 유일성을 보장하기 위해 학번, 교수 번호, 과목 코드와 같은 유일하게 구분할 수 있는 애트리뷰트 삽입
- 개체 및 속성 관계 다이아그램으로부터 각각 4개의 애트리뷰트로 작성
- 릴레이션과 애트리뷰트 이름은 DDL 작성을 위해 한글(영어)로 작성
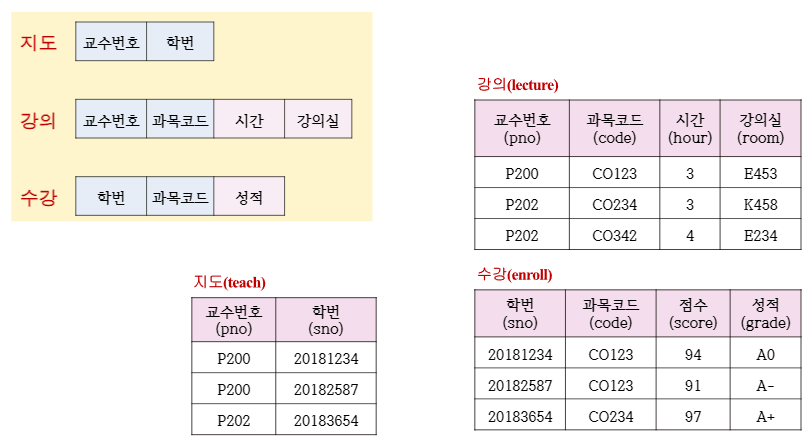
▶관계 릴레이션
- 지도 릴레이션은 교수 번호와 학번으로 교수와 학생 릴레이션 간 관계를 구성 (일 대 다)
- 강의 릴레이션은 교수 번호와 과목 코드로 교수와 과목 릴레이션 간 관계를 구성 (일 대 다)
- 수강 릴레이션은 학번과 과목 코드로 교수와 학생 릴레이션 간 관계를 구성 (다 대 다)
- 강의 릴레이션은 시간과 강의실 애트리뷰트가 추가로 삽입된다고 가정
- 수강 릴레이션은 성적 애트리뷰트가 추가로 삽입된다고 가정
▶데이터베이스의 키(key)
- 키(key)
- 튜플의 유일성
- 실제로는 하나 또는 몇 개의 애트리뷰트만 이용해도 튜플들을 유일하게 식별 가능하다.
- 키(key)는 튜플들을 유일하게 식별할 수 있는 애트리뷰트 집합이다.
- 후보 키(candidate key)
- 릴레이션에서 각 튜플들을 유일하게 식별해주는 몇 개의 애트리뷰트들의 조합이다.
- 유일성
- 몇 개의 애트리뷰트 조합으로 이루어진 후보 키만 비교하더라도 그 튜플을 유일하게 표현할 수 있어야 한다.
- 최소성
- 후보 키는 튜플들을 유일하게 식별하는데 꼭 필요한 애트리뷰트들로 구성된다.
- ex. 학생 테이블에서 <학번>, <성명, 학과>
- 만일 성명만으로 학생 튜플을 유일하게 식별할 수 있다면 <성명, 학과>는 후보 키가 될 수 없다.
- 유일성만 있고 최소성이 없기 때문이다.
- 후보 키가 둘 이상이 되는 경우에 그중에서 어느 하나를 선정하여 기본키(primary key)라 지정하면 나머지 후보 키들은 대체키(alternate key)가 된다.
- ex. <학번> : 기본키, <성명, 학과> : 대체키
- 기본키(primary key)
- 그 키 값을 가진 튜플들을 바로 지정할 수 있다.
- ex. 학생 릴레이션에서 키 값 20181234는 튜플 <20181234, 김철수, 컴퓨터, 010-4654-7654>를 대표하여 지정할 수 있다.
- 슈퍼 키(super key) - *시험
- 유일성(uniqueness)은 만족하지만 최소성(minimality)은 만족하지 않는 애트리뷰트의 집합
- 외래 키(foreign key)
- 강의 릴레이션에서 교수 번호 애트리뷰트는 실제로 교수 릴레이션의 기본키인 교수 번호를 참조하는 외래 키이다.
- 외래 키 : 강의 릴레이션의 교수 번호나 과목 코드 애트리뷰트
▶무결성 제약조건(integrity constraints)
- 개체 무결성 제약조건 (entity integrity constraints)
- 기본키에 속해 있는 애트리뷰트는 널 값이나 중복 값을 가질 수 없다.
- 참조 무결성 제약조건 (referential integerity constraints)
- 릴레이션은 참조할 수 없는 외래 키 값을 가질 수 없다.
- ex. 수강 릴레이션에서 학번 20207779인 튜플이 있다면 참조 무결성이 위배된다.
- 데이터베이스가 삽입, 삭제, 변경 등의 연산을 통해 변경되어도 무결성 제약조건이 유지되어야 한다.
- 과목 릴레이션에서 과목 코드 CO123이 제거 시
- 강의 릴레이션과 수강 릴레이션에 있는 과목 코드 CO123도 함께 삭제되어야 한다.
728x90
'컴퓨터공학 > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 추가된 관계형 대수 (2) | 2022.10.15 |
|---|---|
| [데이터베이스] 관계형 대수 (1) | 2022.10.15 |
| [데이터베이스] B 트리 & B+ 트리 (0) | 2022.10.14 |
| [데이터베이스] 물리적 데이터 (0) | 2022.10.13 |
| [데이터베이스] 데이터베이스 모델링 (*중요) (0) | 2022.10.13 |