
복습하기 위해 학부 수업 내용을 필기한 내용입니다.
이해를 제대로 하지 못하고 정리한 경우 틀린 내용이 있을 수 있습니다.
그러한 부분에 대해서는 알려주시면 정말 감사하겠습니다.
▶5.7 딥러닝이 사용하는 손실 함수
시험 점수의 역할
- 점수가 낮은 학생에게 F학점 또는 낙방과 같은 벌점을 부여하면 자신을 성찰하고 더 열심 히 공부할 동기 부여
- 점수가 낮거나 높거나 비슷한 벌점을 받으면 공정성이 깨지고 공부 의욕을 꺾는다.
신경망 학습도 비슷하다.
- 신경망 가중치가 학생, 손실 함수가 시험 점수에 해당한다.
5.7.1 평균제곱오차
샘플 하나의 오류
- 레이블 y와 신경망이 예측한 값 o의 차이
- e = || y - o || ^ 2
평균제곱오차(MSE, mean-squared error)
- 통계학에서 오랫동안 사용해 온 식을 기계 학습이 빌려다 쓰는 셈이다.
5.7.2 교차 엔트로피
엔트로피 (entropy)
- 확률 분포의 무작위성(불확실성, 정보량)을 측정하는 함수
- 공정한 주사위의 엔트로피는 찌그러진 주사위보다 높다.
- ex) 공정한 주사위의 엔트로피
- -1/6 * log(1/6) * 6 = 1.7918
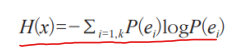
교차 엔트로피 (cross entropy)
- 두 확률 분포 P와 Q가 다른 정도를 측정하는 함수

- ex) 공정한 주사위 P와 찌그러진 주사위 Q(1이 1/2, 나머지는 1/10 확률)의 교차 엔트로피
- -1/6 * (log(1/2) + log(1/10) * 5) = 2.0343
교차 엔트로피 손실 함수
- 교차 엔트로피는 평균제곱오차의 불공정성 문제를 해결해 준다.
- 딥러닝은 주로 교차 엔트로피를 사용한다.
5.7.3 손실 함수의 성능 비교 실험
텐서플로는 30여 종의 손실 함수 제공한다.
Keras documentation: Losses
Losses The purpose of loss functions is to compute the quantity that a model should seek to minimize during training. Available losses Note that all losses are available both via a class handle and via a function handle. The class handles enable you to pas
keras.io
손실 함수 지정하는 세 가지 코딩 방식
model.compile(loss='categorical_crossentropy', optimizer=..., , metrics=...)import tensorflow as tf
model.compile(loss=tf.keras.losses.categorical_crossentropy, optimizer=..., , metrics=...)import tensorflow.keras.losses as ls
model.compile(loss=ls.categorical_crossentropy, optimizer=..., , metrics=...)
평균제곱오차와 교차 엔트로피를 비교하는 코드
- 공정한 비교를 위해 하이퍼 매개변수는 동일하게 설정했다.
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
# MNIST 읽어와서 신경망에 입력할 형태로 변환
(x, y), (xx, yy) = mnist.load_data()
x = x.reshape(60000, 784)
xx = xx.reshape(10000, 784)
x = x.astype(np.float32) / 255.0
xx = xx.astype(np.float32) / 255.0
y = tf.keras.utils.to_categorical(y, 10)
yy = tf.keras.utils.to_categorical(yy, 10)
# 신경망 구조 설정정
n_input=784
n_hidden1=1024
n_hidden2=512
n_hidden3=512
n_hidden4=512
n_output=10
# 평균제곱오차를 사용한 모델
dmlp_mse = Sequential()
dmlp_mse.add(Dense(units=n_hidden1, activation='tanh', input_shape=(n_input,)))
dmlp_mse.add(Dense(units=n_hidden2, activation='tanh'))
dmlp_mse.add(Dense(units=n_hidden3, activation='tanh'))
dmlp_mse.add(Dense(units=n_hidden4, activation='tanh'))
dmlp_mse.add(Dense(units=n_output, activation='softmax'))
dmlp_mse.compile(loss='mean_squared_error', optimizer=Adam(learning_rate=0.0001), metrics=['accuracy'])
hist_mse = dmlp_mse.fit(x, y, batch_size=128, epochs=30, validation_data=(xx, yy), verbose=2)
# 교차 엔트로피를 사용한 모델
dmlp_ce = Sequential()
dmlp_ce.add(Dense(units=n_hidden1, activation='tanh', input_shape=(n_input,)))
dmlp_ce.add(Dense(units=n_hidden2, activation='tanh'))
dmlp_ce.add(Dense(units=n_hidden3, activation='tanh'))
dmlp_ce.add(Dense(units=n_hidden4, activation='tanh'))
dmlp_ce.add(Dense(units=n_output, activation='softmax'))
dmlp_ce.compile(loss='categorical_crossentropy', optimizer=Adam(learning_rate=0.0001), metrics=['accuracy'])
hist_ce = dmlp_ce.fit(x, y, batch_size=128, epochs=30, validation_data=(xx, yy), verbose=2)
# 두 모델의 정확률 비교
res_mse = dmlp_mse.evaluate(xx, yy, verbose=0)
print('mse = ', res_mse[1] * 100)
res_ce = dmlp_ce.evaluate(xx, yy, verbose=0)
print('ce = ', res_ce[1] * 100)▶5.8 딥러닝이 사용하는 옵티마이저
손실 함수의 최저점을 찾아주는 옵티마이저
- 표준에 해당하는 SGD 옵티마이저를 개선하는 두 가지 아이디어
- 모멘텀 (momentum)
- 적응적 학습률 (adapative learning rate)
5.8.1 모멘텀을 적용한 옵티마이저
물리에서 모멘텀
- 이전 운동량을 현재에 반영(관성과 관련)
- 옵티마이저에 적용하면 뚜렷한 성능 향상
모멘텀의 원리
- 모멘텀에서는 이전 방향 정보 v를 같이 고려(α는 [0,1] 사이에서 조절)
- α=0는 고전적 SGD, α가 1에 가까울수록 이전 정보에 큰 가중치 부여
- 보통 α=0.5, 0.9를 사용
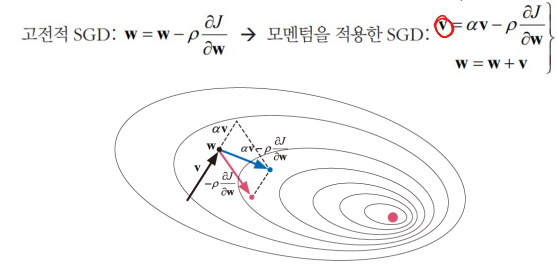
네스테로프(Nesterov) 모멘텀
- 현재 점 w에서 미분하는 대신,
- 이전 정보 αv를 이용해 다음에 이동할 곳 w^(hat)을 예측하고 그곳에서 그레이디언트를 계산한다.
텐서플로에서 모멘텀 적용
- 기본값은 모멘텀 적용 않고 네스테로프 적용 안 한다.
- [SGD 옵티마이저의 API]
tensorflow.keras.optimizer.SGD(learning_rate=0.01, momentum=0.0, nesterov=False, name='SGD', **kwargs)- 만일 학습률 0.0001, 모멘텀 0.9, 네스테로프 적용하려면
tensorflow.keras.optimizer.SGD(learning_rate=0.0001, momentum=0.9, nesterov=True)
5.8.2 적응적 학습률을 적용한 옵티마이저
그레이디언트는 최저점의 방향은 알려주지만 이동량에 대한 정보가 없다.
- 작은 학습률을 곱해 조금씩 보수적으로 이동한다.
- 학습률이 너무 작으면 학습에 많은 시간을 소요한다.
- 학습률이 너무 크면 진동 가능성이 있다.
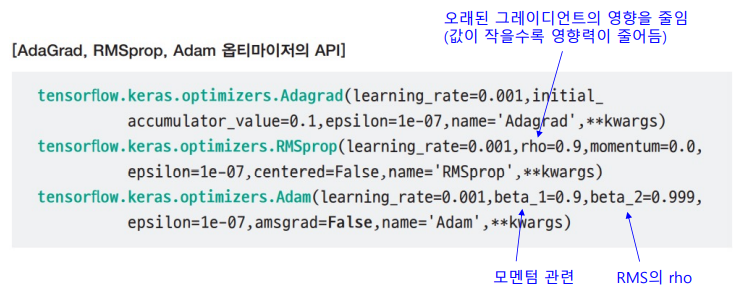
적응적 학습률
- 상황에 맞게 학습률을 조절하는 방법
- Adagrad : 이전 그레이디언트를 누적한 정보를 이용해 학습률을 적응적으로 설정하는 기법
- RMSprop : 이전 그레이디언트를 누적할 때 오래된 것의 영향을 줄이는 정책을 사용해 AdaGrad를 개선한 기법
- Adam : RMSprop에 모멘텀을 적용해 RMSprop를 개선한 기법
옵티마이저의 API
▶5.9 좋은 프로그래밍 스킬
▶5.10 교차 검증을 이용한 하이퍼 매개변수 최적화
성능 그래프를 보면 전반적으로 Adam이 우세한데 마지막 세대에서 RMSprop이 운이 좋게 우승
교차 검증은 우연을 배제하는데 효과적이다.
5.10.1 교차 검증을 이용한 옵티마이저 선택
텐서플로는 교차검증을 지원하는 함수가 없어 직접 작성해야 한다.
k개로 분할하는 일은 sklearn의 KFold 함수를 이용한다.
def cross_valication(opt):
accuracy = []
for train_index, val_index in KFold(k).split(x_train):
xtrain, xval = x_train[train_index], x_train[val_index]
ytrain, yval = y_train[train_index], y_train[val_index]
dmlp = build_model()
dmlp.compile(loss='categorical)crossentropy', optimizer=opt, metrics=['accuracy'])
dmlp.fit(xtrain, ytrain, batch_size=batch_siz, epochs=n_epoch, verbose=0)
accuracy.append(dmlp.evaluate(xval, yval, verbose=0)[1])
return accuracy
5.10.2 과다한 계산 시간과 해결책
교차 검증은 많은 시간을 소요한다.
- 계산 시간 분석
- for문은 k번 반복한다.
- fit 함수는 가장 많은 시간을 소요한다.
- fit가 소요하는 시간을 t라 하면 k * t만큼 지나야 옵티마이저 하나를 처리한다.
- 옵티마이저가 4개이므로 4kt 시간 소요 (t = 5분, k = 5라면 4 * 5 * 5 = 100분 소요)
- k = 10으로 늘리고 n_epoch을 20에서 100으로 늘리면 1000분 소요
실제에서는
- 데이터 크기가 MNIST에 비해 수십~수백 배
- 더 많은 하이퍼 매개변수를 동시에 최적화
- ex) 옵티마이저 4개, 학습률 7개, 미니배치 크기 6개라면 총 168개의 조함
해결책
- GPU 사용
- 욕심을 버린다. (경험을 통해 조합의 수를 축소)
'컴퓨터공학 > 인공지능' 카테고리의 다른 글
| [인공지능] 6장. 컨볼루션 신경망과 컴퓨터 비전2 (0) | 2023.04.13 |
|---|---|
| [인공지능] 6장. 컨볼루션 신경망과 컴퓨터 비전1 (1) | 2023.04.13 |
| [인공지능] 5장. 딥러닝과 텐서플로2 (0) | 2023.04.12 |
| [인공지능] 5장. 딥러닝과 텐서플로1 (1) | 2023.04.10 |
| [인공지능] 4장. 신경망 기초3 (3) | 2023.04.06 |