
복습하기 위해 학부 수업 내용을 필기한 내용입니다.
이해를 제대로 하지 못하고 정리한 경우 틀린 내용이 있을 수 있습니다.
그러한 부분에 대해서는 알려주시면 정말 감사하겠습니다.
지난 글에 이어서 작성해 보도록 하겠습니다.
2022.11.23 - [컴퓨터공학/데이터베이스] - [데이터베이스] 데이터베이스 설계
[데이터베이스] 데이터베이스 설계
복습하기 위해 학부 수업 내용을 필기한 내용입니다. 이해를 제대로 하지 못하고 정리한 경우 틀린 내용이 있을 수 있습니다. 그러한 부분에 대해서는 알려주시면 정말 감사하겠습니다. ▶설계
dhalsdl12.tistory.com
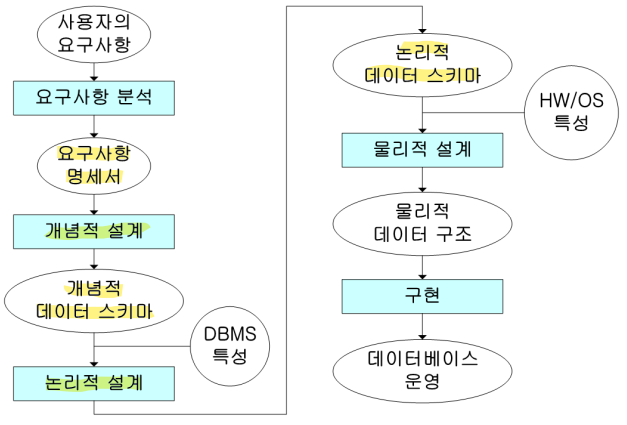
▶논리적 설계(logical design)
개념적 설계에서 생성된 개념적 데이터 스키마로부터 목표 DBMS가 처리할 수 있는 스키마를 생성하는 것이다.
- 요구사항 명세서를 만족해야 한다.
- 무결성, 일관성, 제약조건도 만족해야 한다.
3단계를 거쳐서 수행된다.
- 논리적 데이터 모델로 변환
- 트랜잭션 인터페이스 설계
- 스키마의 평가 및 정제
1. 논리적 데이터 모델로 변환
개념적 데이터 스키마를 목표 DBMS에 맞는 스키마, 즉 논리적 데이터 모델로 변환한다.
- 이 변환 과정을 논리적 데이터 모델링이라고 한다.
- 데이터 모델에는 관계형, 계층, 네트워크, 객체지향, 객체 관계형 모델들을 모두 포함한다.
이 단계의 결과 : 목표 DBMS의 DDL로 기술된 스키마
- 이 DDL에는 물리적 설계 단계에서 결정해야 될 매개변수들이 포함될 수 있으므로
- 완전한 스키마 정의는 물리적 설계 단계까지 보류한다.
2, 3단계
트랜잭션 인터페이스 설계
- 트랜잭션의 전체적 골격(skeleton)을 개발하고 인터페이스를 정의한다.
- 트랜잭션에 대한 데이터 접근 방법을 기술한다.
스키마의 평가 및 정제
- 성능 평가는 정략적 정보와 성능평가 기준에 따라서 수행한다.
- 정량적 정보 : 데이터의 크기, 처리 빈도수, 처리 작업량 등
- 성능평가 기준 : 논리적 레코드의 접근, 데이터 전송량, DB의 크기 등
- 필요한 경우 인덱스나 해싱 기법 등을 사용해 성능을 개선시킨다.
독립된 릴레이션으로 관계를 표현
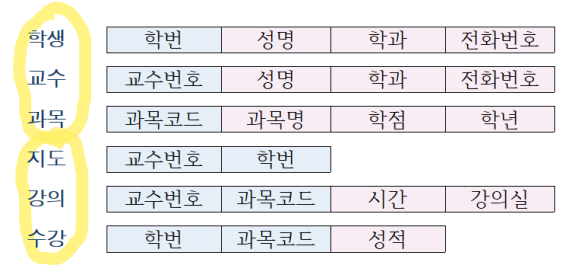
공통 애트리뷰트로 관계를 표현

독립된 릴레이션으로 관계를 표현하지 않고,
두 릴레이션에 공통되는 애트리뷰트(키)를 공통으로 갖게 함으로써 묵시적으로 관계를 나타낼 수도 있다.
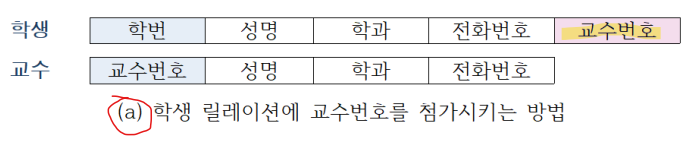
학생 릴레이션에 '교수 번호'를 첨가시키거나(a), 교수 릴레이션에 '학번'을 첨가시켜(b) 관계를 묵시적으로 표현
어떤 방법을 선택할지는 설계자의 선택사항이다.
- 고려할 사항 : 데이터 중복과 데이터 처리의 효율성
- (a)의 경우 데이터 중복이 크게 생기지 않는다.
- (b)의 경우 중복이 크게 생긴다.
- 1:n인 경우 n 쪽의 릴레이션에 키를 첨가시키는 것이 효율적이다.
▶물리적 설계(physical design)
논리적 데이터 스키마로부터 효율적인 내부 스키마를 설계하는 것이다.
- 성능에 중대한 영향을 미치므로 효율성이 강조된다.
- 트랜잭션의 상세 설계도 병행하여 수행된다.
물리적 데이터 구조의 기본적인 데이터 단위는 저장 레코드(stored record)
하나의 파일(file): 한 타입의 저장 레코드들의 집합
물리적 설계에는 다음과 같은 설계들이 포함된다.
- 저장 레코드 양식 설계(stored record format design)
- 레코드 집중화(record clustering)
- 접근 경로(access path)
- 저장 공간 할당(storage space allocation)
★저장 레코드 양식(format) 설계 시 고려사항
- 데이터 타입
- 데이터 값의 분포
- 사용될 응용
- 접근 빈도
저장 레코드에 대한 데이터 표현과 압축에 관한 정보도 포함된다.
접근 빈도수에 따라 그룹을 달리해 물리적으로 상이하게 저장하는 것도 포함된다.
레코드 집중화(record clustering)
논리적으로 관련이 깊은 레코드들을 물리적으로 근접하도록 저장해 물리적 순차성을 지원한다.
연속된 레코드의 검색을 요구할 때 빠른 접근이 가능하다.
블록 크기의 선정
- 순차 처리(sequential processing)가 주가 되면 큰 블록을 사용하는 것이 유리하다.
- 임의 접근 처리(random processing)가 주가 되면 작은 블록을 사용하는 것이 유리하다.
접근 경로(access path)
저장된 데이터의 검색과 저장을 가능하게 한다.
- 저장 구조 : 주로 인덱스를 통한 접근 방법과 데이터 파일을 정의한다.
- 탐색 기법 : 주어진 응용을 위한 적절한 접근 경로를 정의한다.
기본 접근 경로와 보조 접근 경로로 나뉜다.
- 기본 접근 경로(primary access path)
- 기본키를 기본으로 한 기본 인덱스를 이용하는 것
- 초기 레코드 적재, 레코드의 물리적 위치, 기본키를 통한 검색
- 주요 응용들이 기본 접근 경로를 이용해서 처리되도록 설계
- 보조 접근 경로(secondary access path)
- 보조키에 기반을 둔 보조 인덱스를 통해 저장 레코드를 접근
- 접근 시간은 줄일 수 있으나 저장 공간을 추가로 사용하고, 인덱스 관리가 복잡해진다.
상용 DBMS는 성능 향상을 위해 여러 가지 tool을 지원한다.
- 인덱싱 기법, 레코드 집중화, 포인터, 해싱 등이 포함
물리적 데이터 구조 설계 시 고려사항
- 트랜잭션 응답 시간
- 저장공간의 효율화
- 트랜잭션 처리도(throughput)
- 단위 시간에 DBMS가 처리할 수 있는 평균 트랜잭션 수
물리적 설계의 평가를 위해 시뮬레이션이나 프로토타입과 같은 기법을 많이 사용한다.
DBMS는 성능 평가를 위해 system catalog(log file)에 통계 데이터를 저장한다.
- 트랜잭션 발생 수, 입출력 연산, 페이지나 인덱스 수, 인덱스 사용 빈도에 대한 정보가 저장된다.
▶구현
목표 DBMS의 DDL로 기술된 명령문이 컴파일되고 실행된다.
- 데이터베이스 스키마와 빈 데이터베이스 파일을 생성한다.
DB에 데이터를 적재(loading) 시킨다.
- 만일 기존 파일이 있다면 변환 유틸리티를 사용한다.
DB의 트랜잭션은 응용 프로그래머에 의해 구현된다.
DB 설계 및 구현이 끝나면 DB 운영 단계로 넘어간다.
'컴퓨터공학 > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 회복 (1) | 2022.11.25 |
|---|---|
| [데이터베이스] 무결성, 보안 (0) | 2022.11.25 |
| [데이터베이스] 데이터베이스 설계 (1) | 2022.11.23 |
| [데이터베이스] 데이터베이스 정규화 - 정규형 (2) | 2022.11.12 |
| [데이터베이스] 데이터베이스 정규화 (2) | 2022.11.12 |